Google CloudのステートフルMIGでMongoDBレプリカセットを構築して無停止ローリングアップデートを実現する
2025-04-11

こんにちは、株式会社EukaryaのSREチームのkekeです。
弊社では、国土交通省の分野横断的なDX推進プロジェクトであるProject LINKSのデータ構築基盤「LINKS Veda」のバックエンドとしてRe:Earth CMSを提供しています。そのRe:Earth CMSは、データベースとしてMongoDBを採用しており、今回はGoogle Cloud上でSelf-HostedなMongoDBのレプリカセットを構築しました。その際、高い信頼性と運用的コストが少ないことが求められましたが、参考となる事例が少ない中で、ステートフルManage instance groups (MIG)で構築したシステムを紹介します。
なぜSelf-Hostedなのか?
弊社では、インフラストラクチャの構築・運用において、Cloud Runなどのサーバーレス技術やMongoDB Atlasなどのマネージドサービスを積極的に採用しています。これにより、経済的・運用的コストを最小限に抑えながら、エンジニアが機能開発などビジネスロジックに集中できる環境を実現しています。サービスの成長に伴い、インフラストラクチャの管理はCTOを含む数名のメンバーによって効率的に行われています。
しかし、今回セルフホスティングを選択せざるを得なかった理由は、MongoDB Atlasを含む私たちの技術スタックにとって実用的なマネージドサービスが、日本政府認定のISMAPクラウドサービス一覧に含まれていなかったためです。
認定されているAmazon Web Services(AWS)にはMongoDB互換のAWS DocumentDBが存在します。ただし、これは内部ネットワークアクセス(同一ネットワーク空間内からのアクセス)に制限されており、Cloud Runでホスティングしているサービスからアクセスするには、VPN接続やリバースプロキシを経由する必要があります。これにより、マルチクラウド構成やVPNコネクタなどが必要となり、システムの複雑化が進むリスクがあります。少人数のチームでは、このような構成を運用することは現実的ではありませんでした。
さらに、MongoDB Atlasの報告によると、2023年11月時点でAWS DocumentDBのMongoDBに対する互換性はわずか34%程度に過ぎません。これらの理由から、AWS DocumentDBの互換率によって発生するアプリケーションの制約や大幅な変更を避けたいと考えました。Microsoft AzureのAzure Cosmos DB for MongoDBについても同様の懸念がありました。
以上の理由により、MongoDBレプリカセットの自前運用には運用負荷が伴うものの、総合的に評価した結果、Google Cloud上でのセルフホスティングが最適な選択と判断しました。そこで、限られたリソースの中で、最大限の高可用性と信頼性を備えたシステムを構築することを目指しました。
ステートフルManaged Instance Groups (MIG)とは?
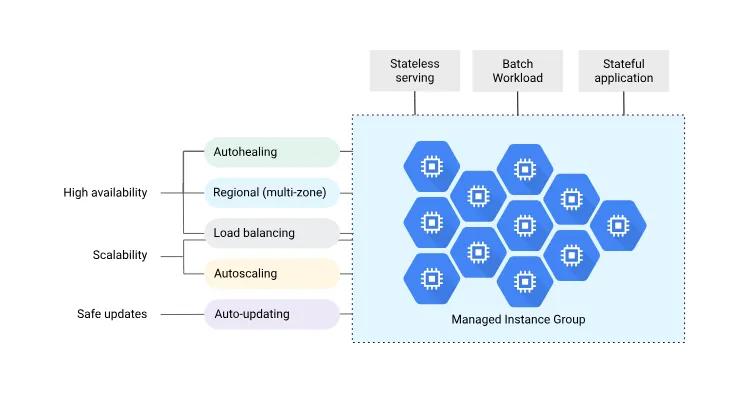
Managed Instance Groups (MIG)とは、Google Cloudが提供する機能で、同一の設定を持つ複数のインスタンスをグループとして管理できるGoogle Cloudサービスです。AWSであればAuto Scaling Groupが似たような機能を提供しています。
本番環境で運用されるサーバーは一般的に高可用構成(HA、High-Availability)を取り、通常2つ以上のインスタンスで構成されます。この際、単に複数のインスタンスを個別に構築するのではなく、MIGを使用することで以下のような利点が得られます。
- 自動スケーリング:負荷に応じてインスタンス数を自動的に増減できる。
- オートヒーリング:ヘルスチェックに失敗した場合、インスタンスを自動で再起動・再作成できる。
- 継続的デリバリー:インスタンステンプレートで設定を管理でき、変更時には自動ローリングアップデートなどのデプロイメント手法が適用可能。
- 高可用性:障害発生時に自動的に新しいインスタンスを起動し、サービスの継続性を確保できる。
- 分配形態(トポロジー)の指定:複数のインスタンスを均等にマルチゾーンに展開するなど、特定のトポロジーを指定して運用可能。
同一の設定を持つインスタンスを構築するのであれば、MIGを使うことによって多くの運用管理タスクを自動化でき、システムの信頼性と効率性を向上させることができます。
しかし、MongoDBのようなステートフルなアプリケーションの場合、(この通常の)MIGでは十分ではありません。たとえば、MongoDBのレプリカセットを構成する際には、ノード(インスタンス)が再作成される場合でも、以下の要件を満たす必要があります。
- 再作成前のノードにアタッチされていた永続ディスクが新しいノードにもアタッチされる。
- 同じインスタンス名(内部DNS名)で再作成され、他のノードが再作成後も名前解決できる。
- プライマリノードがダウンした場合にフェイルオーバーが自動的に行われ、継続して読み書きを行うことができる。
そこで登場するのがステートフルMIGです。ステートフルMIGは、通常のMIGの機能に加えて、ステートフルなワークロードに対応するための諸々の機能を提供します。ステートフルMIGは以下の要素で構成されています。
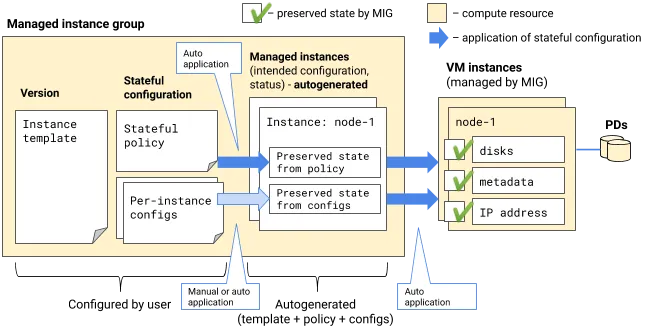
具体的には、永続ディスクの管理、固定的なインスタンス名や内部IPアドレスの割り当て、そしてインスタンス固有の設定の保持などが可能になります。これらの機能により、MongoDBのようなステートフルなアプリケーションでも、MIGの利点を活かしつつ、データの一貫性と可用性を確保することができます。Kubernetesに馴染み深い方であれば、MIGはDeployments、ステートフルMIGはStatefulSetsに対応していると思っていただければ理解しやすいと思います。
また、MIGには、単一ゾーンにデプロイする(通常の)MIGと単一リージョンにデプロイをするリージョン MIGが存在します。高可用性を求める場合は、リージョン(マルチゾーン)構成にすることが多いので、今回はリージョンMIGを選択しました。なお、リージョン MIGであっても、トポロジーに SINGLE_ZONE を指定することによって単一ゾーンだけにデプロイすることも可能ですが、ゾーンをあとから変更することはできません。
ステートフルMIGの詳細な仕組みについては公式ドキュメント「How stateful MIGs work」をご参照ください。
リージョンMIGの更新は各ゾーンが同期的に行われない
リージョン(マルチゾーン)構成を採用することで、1つのゾーンに障害が発生しても可用性を維持できるため、特に高可用性が求められるアプリケーションにとって望ましい構成です。リージョン MIGはこの要件を満たすための構成ですが、インスタンス数が少ない場合、特にインスタンス数がゾーンの数より少ない場合には注意が必要です。
インスタンス名を固定した更新やステートフルMIGの変更の場合、同じホスト名やディスクが同時に存在しえないので、更新時に追加できるインスタンス(サージ数)数は常に0にする必要があり、オフライン上限インスタンス数をゾーン数以上に設定しなければならないです。
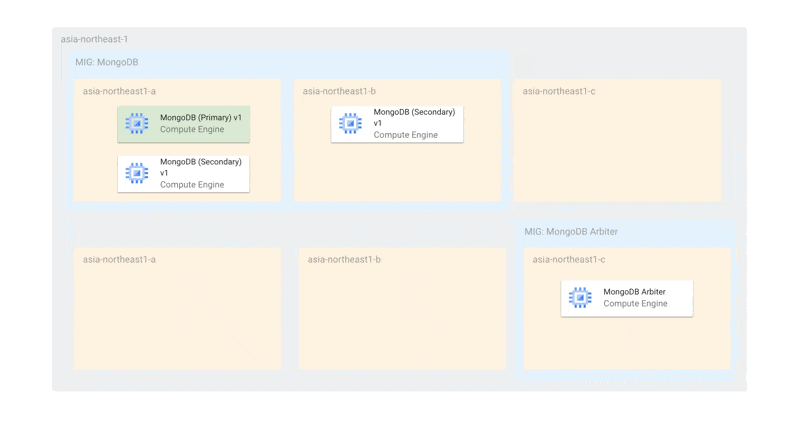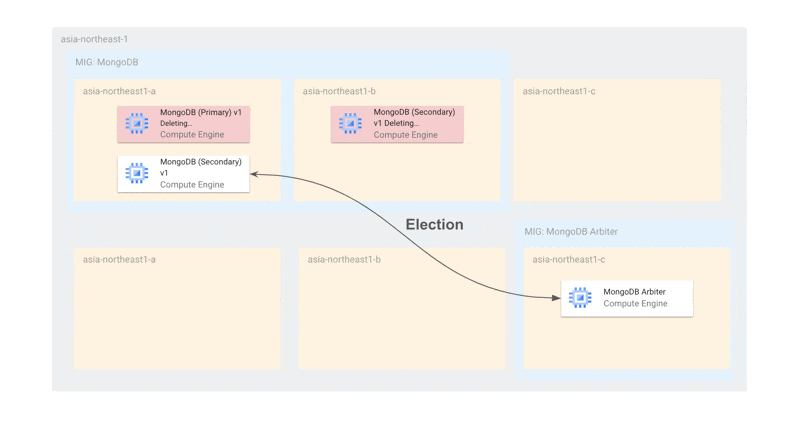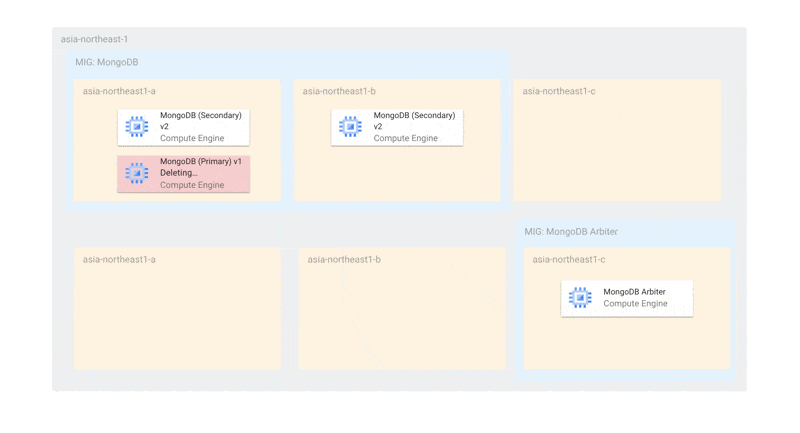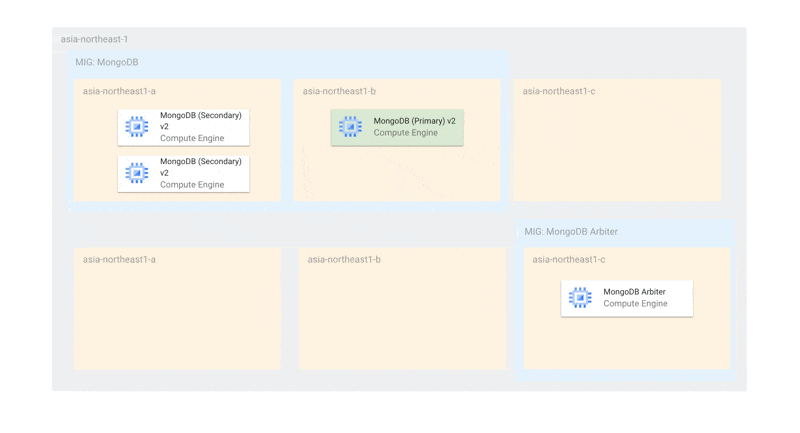
例を挙げると、3つのゾーンにそれぞれ1つのインスタンスがある場合、オフライン上限インスタンス数はゾーンと同じ数の3またはそれ以上になります。可用性を担保しながら更新を行う場合、以下のように各ゾーンのインスタンスを1台ずつ更新することを望むでしょう。
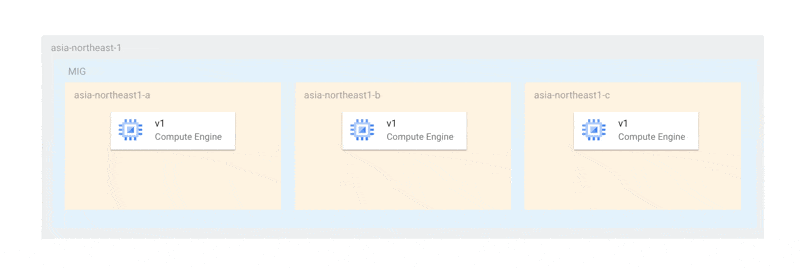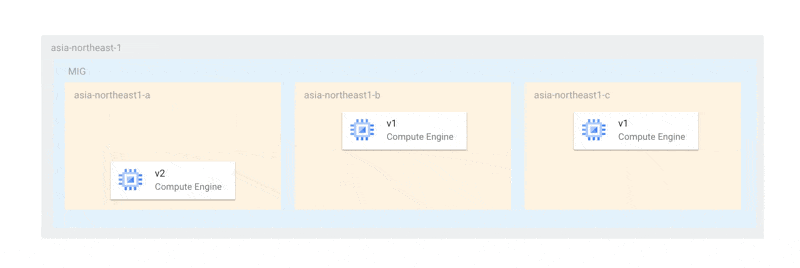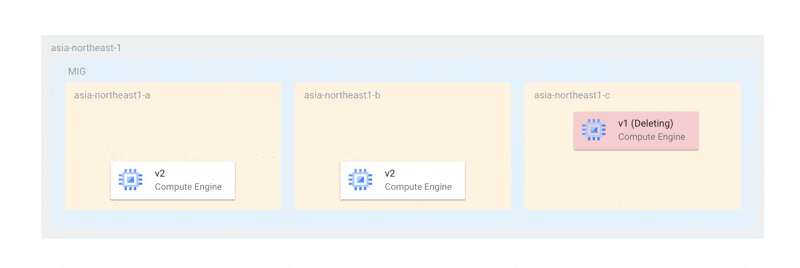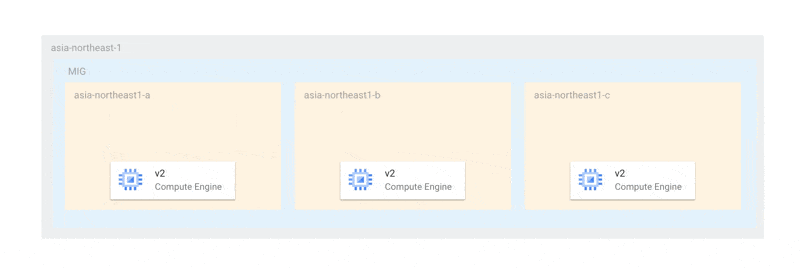
この方法であれば、少なくともプライマリ選出が行える状態の2台が稼働しており、更新のいかなる場合においても、可用性が損なわれることはありません。しかし、現在の仕様では、更新は以下のように各ゾーンで一斉に行われます。
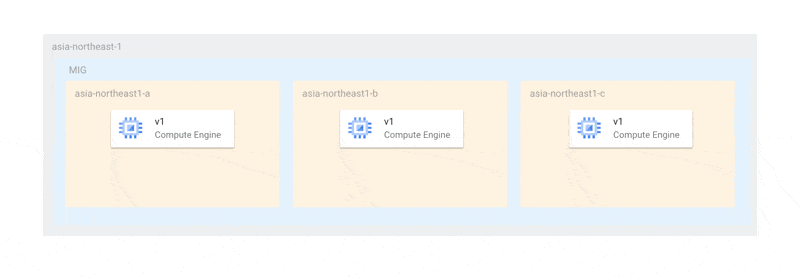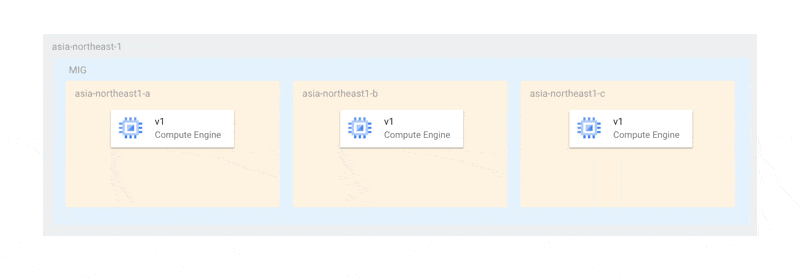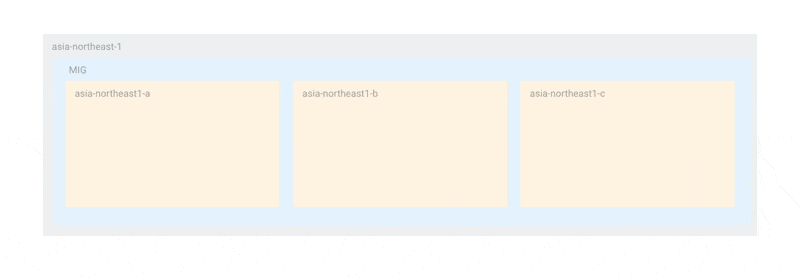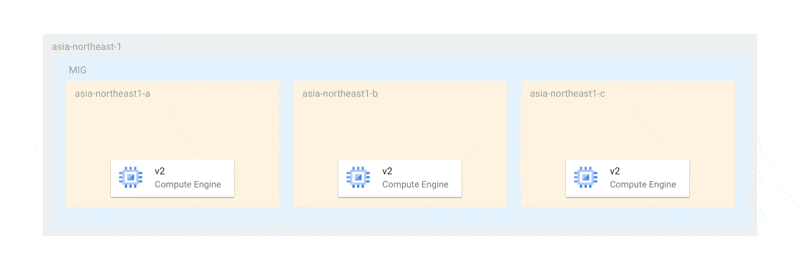
これは、オフライン上限インスタンス数がゾーンの数と同じまたはそれ以上でなければならない、という制限に起因しています。そのため、今回のように各ゾーンにインスタンスが1台しかない場合、最悪すべてのインスタンスが同時に停止する可能性があります。仮に、全停止を避けられたとしても、MongoDBのプライマリ選出ができるノード数が足りなくなるとレプリカセットが機能不全に陥ってしまいます。
この問題を回避する以下のいくつかの方法があります。
- 単一ゾーンのMIGの使用(シングルゾーン構成)
- トポロジーに
SINGLE_ZONEを指定し、ダウンを許容するインスタンス数をゾーン数未満に設定 (同じくシングルリージョン構成) - プライマリー選出の要件ノード数を満たし、かつ、各ゾーンに2台以上存在するようにインスタンス数を増やす
- Hashicorp Consulやロードバランサなどの導入により、インスタンス名に依存しないレプリカセットを構築する
どの方法も信頼性が低下する、または経済的・運用的コストが増加するため、現実的ではありませんでした。
MongoDB Arbiterを活用したリージョン構成
MongoDB (Replica Set) Arbiterとは、レプリカセット内でプライマリノードの選出をサポートする役割を持つ軽量なノードです。Arbiter自体はデータを保存せず、プライマリー選出の投票にのみ参加します。これにより、データが保持されないためリソースをほとんど消費せず、可用性を高めつつコストを抑えることができます。奇数のノード数を確保してプライマリの選出プロセスをスムーズに行うために使用されます。
前述の課題から、現時点ではArbiterを活用して以下のような構成になっています。
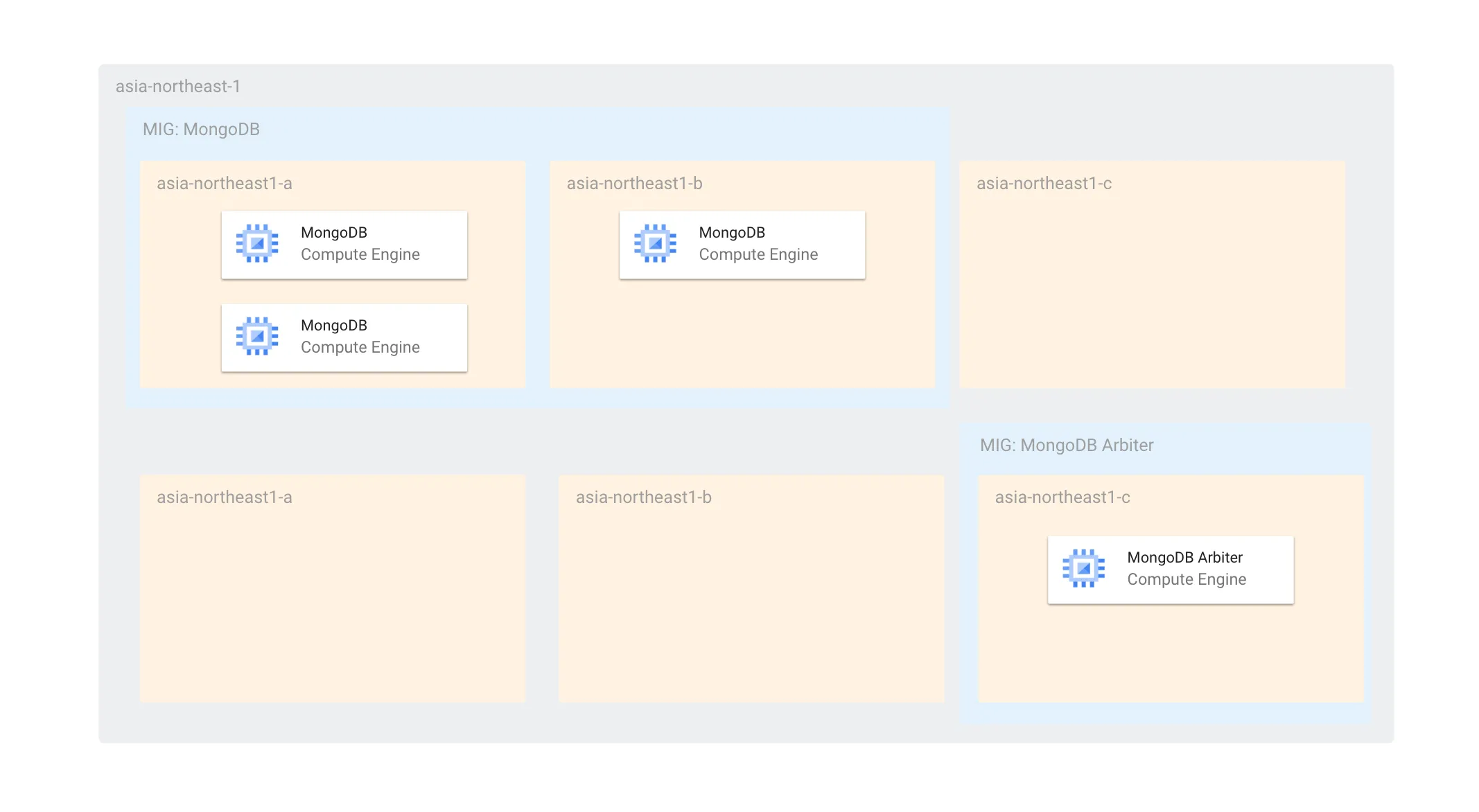
Arbiterを含めるとMongoDBのゾーンあたりのノード数が2(1を超える状態)であるため、更新時にも同時に最大2台しかオフラインにならず、プライマリー選出ができる状態です。また、MongoDBのMIGはArbiterの更新に対して独立しているため、仮にArbiterがすべて停止していても、MongoDBのインスタンスだけで十分にプライマリー選出を行うことができます。
また、単一ゾーン障害に関しても耐えられるようになっています。障害時には、Arbiterと残されたMongoDBでプライマリー選出ができるようになっています。MIGのトポロジーを EVEN にしているため、単一ゾーンにインスタンスが偏らないことが保証されています。
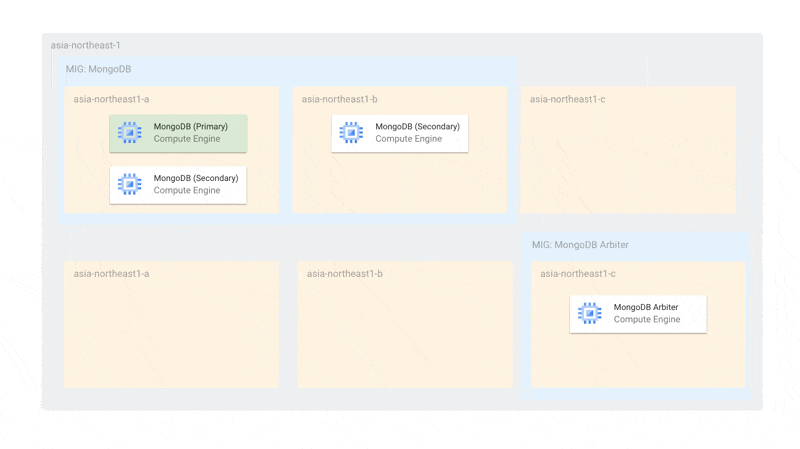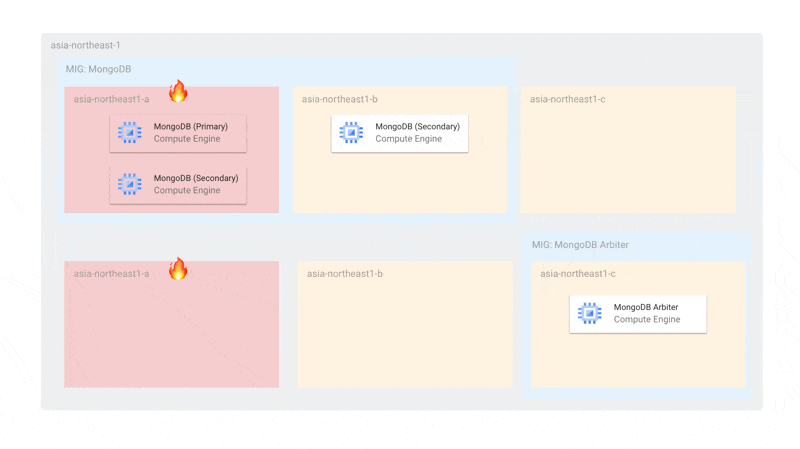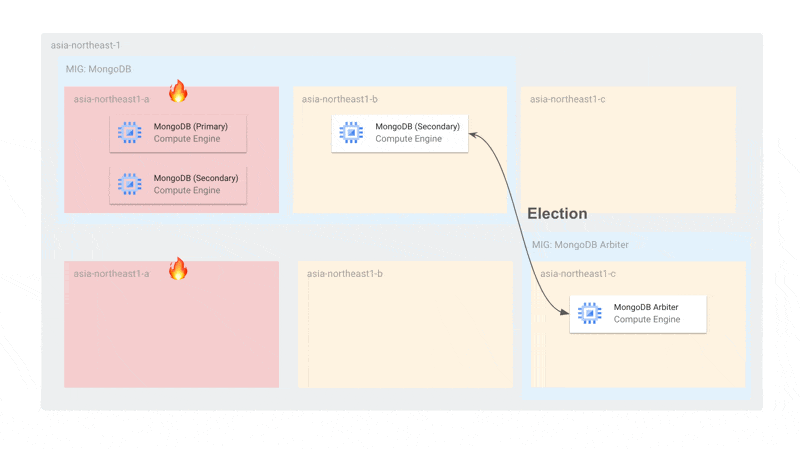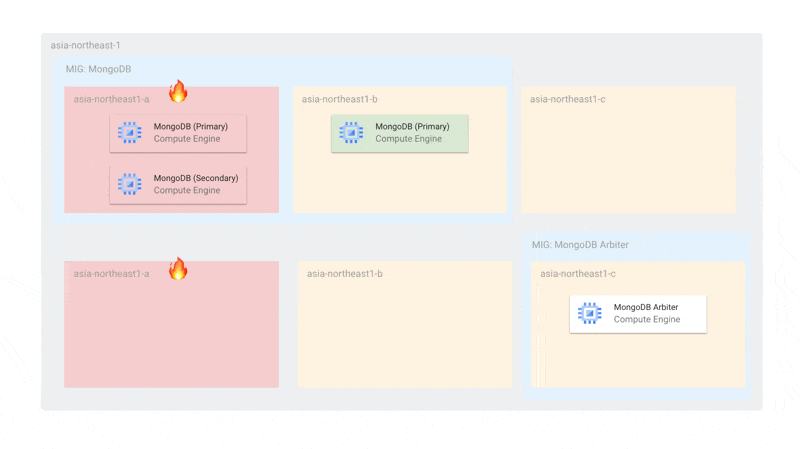
使用するゾーンをMongoDBとMongoDB Arbiterで分けているのは、MongoDBが2台存在するゾーンにArbiterがスケジューリングされてしまうと、そのゾーン障害があったときにプライマリー選出ができなくなるからです。ArbiterとMongoDBが同じゾーンに存在しないようにゾーンを分けています。
なお、各ノード間の認証にはキーファイル認証を使用し、モニタリングにはGoogle CloudのOps Agentを採用していますが、MIG以外の詳細については別の機会に紹介し、ここでは割愛させていただきます。
ステートフルMIGの作成
私たちは、リソースの管理にTerraformを採用しているため、インフラ構成をコードとして管理しています。以下に、Terraformでの宣言例を示します。
resource "google_compute_region_instance_group_manager" "mongodb" {
base_instance_name = "mongodb"
name = "mongodb"
distribution_policy_zones = ["asia-northeast1-a", "asia-northeast1-b", "asia-northeast1-c"]
region = "asia-northeast1"
target_size = 3
# オートヒーリング
auto_healing_policies {
initial_delay_sec = 90 # seconds
health_check = google_compute_health_check.mongodb.id
}
named_port {
name = "mongodb"
port = 27017
}
# 永続ディスク
stateful_disk {
device_name = "mongodb-0"
delete_rule = "NEVER"
}
version {
instance_template = google_compute_instance_template.mongodb.self_link_unique
}
update_policy {
instance_redistribution_type = "NONE"
max_surge_fixed = 0
max_unavailable_fixed = 2
minimal_action = "REFRESH"
most_disruptive_allowed_action = "REPLACE"
replacement_method = "RECREATE"
type = "PROACTIVE"
}
}
以下の設定ポイントがあります。
stateful_disk: 永続ディスクを指定しています。ステートフルMIGの場合、インスタンスが再作成されても、再作成前にアタッチされていたディスクがアタッチされます。- この設定によって、通常のMIGではなくステートフルMIGとして作成されます。さらに、プライベートIPを固定する
stateful_internal_ipなどの設定でも、ステートフルMIGとして作成されます。
- この設定によって、通常のMIGではなくステートフルMIGとして作成されます。さらに、プライベートIPを固定する
update_policy: 次のセクションで紹介します。
他の設定項目は、通常のMIGと変わりありません。MongoDB Arbiterも同様に宣言していますが、Arbiterはデータを保持しないため、永続ディスクはアタッチしていません。
Update Policy
アップデートポリシーは、インスタンスの更新方法を定義するための設定です。
主な設定項目は以下の通りです。
instance_redistribution_type:リージョンMIG専用の設定で、ゾーン間のインスタンス偏りを是正する再分配方法を指定します。ステートフルMIGではインスタンスの状態を保持する必要があるため別ゾーンへの移動ができず、NONEのみ指定可能です。max_unavailable_fixed: オフライン上限インスタンス数で、ゾーンの数以上にする必要があります。replacement_method:インスタンス名(内部DNS名)やステートフルな設定を保持するため、RECREATE(再作成)に指定する必要があります。同一ホスト名の複数インスタンス共存は不可能なためです。- 同じ理由で、
max_surge_fixedは0、max_unavailable_fixedはゾーン数以上に設定する必要があります。
- 同じ理由で、
type:インスタンステンプレート更新時のインスタンス更新方法を指定します。PROACTIVE(自動)を選択し、インスタンステンプレートの更新が常に反映されるようにしています。
この構成により、インスタンス名を保持したまま再作成が伴う更新でも、可用性を損なわずに自動で更新を続けることが可能です。オフラインになるインスタンス数の上限はゾーンの数である2に設定しており、最低でも1台のMongoDBが常に稼働している状態を確保しています。
Container Optimized OS (COS)はコンテナを実行できるがモニタリングが難しい
Google Cloudでは、Fedora CoreOSに似たコンテナランタイム環境として、Chromium OSをベースとしたContainer-Optimized OS (COS)を提供しており、GCE上で簡単にコンテナを実行できます。これにより、たとえばMongoDBをDocker Hubから取得して、シンプルにGCE上でデプロイすることが可能です。
しかし、運用フェーズでのモニタリングやメトリクス管理にはいくつかの課題がありました。
特に問題となったのは、Google Cloud Ops AgentがCOSではサポートされておらず、ホスティングしたアプリケーションのモニタリングが非常に難しい点です。
ログはCloud Loggingを使って取得できるものの、MongoDBの特有なメトリクス、たとえばコレクション数やレプリケーションラグなど、詳細な情報を得るには工夫が必要です。MongoDB ExporterやOpenTelemetry Agentなどを使用し、Cloud Monitoringに統合する方法もあります。しかし、この場合、Google CloudのManaged Service for Prometheusを導入し、カスタムメトリクスを収集・可視化する必要があり、運用にオーバーヘッドが生じる可能性が高くなります。
COSの利点はそのシンプルさにある一方で、モニタリングやメトリクス収集といった運用管理においては追加のコストがかかるため、最終的にMongoDBをGCEのVMインスタンス上で直接バイナリとして実行する方法に切り替えることにしました。
現在、イメージはHashicorp Packerを使用して作成し、Infrastructure as Code(Images as Code)を実現しています。これにより、再現性がある形でGoogle Cloudのネイティブなモニタリングツールを使って効率的に監視・運用が可能となります。
おわりに
Google Cloud上にMongoDBのレプリカセットを構築する際、通常のMIGではステートフルManaged Instance Groups (MIG)を採用しました。これにより、永続ディスクの保持やインスタンス名、内部IPの固定が可能になり、MongoDBのレプリカセットの安定性を確保しつつ、MIGのローリングアップデートの機能を使うことができ、ダウンタイムなく変更をリリースし続けられています。
リージョン MIGの更新において、インスタンス名(内部ホスト名)を保持しつつ、ゾーンの数よりオフライン上限インスタンス数を許容できれば、自動でダウンタイムなしに更新を行える可能性があります。しかし、現在の仕様ではこれを実現できず、ぜひとも実装してほしい機能です。
弊社はWebGISなどの開発・提供を行っており、グラフィカルなコンテンツや話題が多い一方で、信頼性と堅牢性の高いサービスを支えるために、インフラストラクチャやSREにも力を入れています。今回の構成にもまだ課題はありますが、さらなる自動化や高可用性を目指して挑戦を続けたいと思います。
Eukaryaでは様々な職種で採用を行っています!OSSにコントリビュートしていただける皆様からの応募をお待ちしております!
Eukarya is hiring for various positions! We are looking forward to your application from everyone who can contribute to OSS!
Eukaryaは、Re:Earthと呼ばれるWebGISのSaaSの開発運営・研究開発を行っています。Web上で3Dを含むGIS(地図アプリの公開、データ管理、データ変換等)に関するあらゆる業務を完結できることを目指しています。ソースコードはほとんどOSSとしてGitHubで公開されています。
➔ Re:Earth / ➔ Eukarya / ➔ note / ➔ GitHub
Eukarya is developing and operating a WebGIS SaaS called Re:Earth. We aim to complete all GIS-related tasks including 3D (such as publishing map applications, data management, and data conversion) on the web. Most of the source code is published on GitHub as OSS.