GoとGCSで100GBの巨大zipファイルを展開する
2024-06-21

はじめに
ファイルをアップロードすることができる機能を持ったWebアプリケーションやクラウドサービスは世の中に多数あります。しかし、アップロードしたzipファイルを自動で展開(解凍)してくれて、中身のファイルが閲覧できる機能を持ったサービスは、あまり多くはないかもしれません。
もし、Google Cloud上で、zipファイルをアップロードし自動的に展開してGCSに配置するシステムを作るとしたら、どうやって実現すればよいでしょうか。たとえ100GBのzipファイルでも問題なく展開できるようにするには?
そんな難題に挑み、GCSにアップロードされた100GB級のzip/7zファイルを自動的に展開することができるシステムをGoで実装し、プロダクションレベルで実現しました。その技術について解説します。
背景
Eukaryaでは、国土交通省が主導しているProject PLATEAU(全国自治体の3D都市モデルのオープンデータを整備する事業)の一環として、データの閲覧がWeb上で行えるPLATEAU VIEWを開発・運用しています。
このPLATEAU VIEWにはデータ可視化機能だけでなく、データ管理基盤(CMS = Content Management System)も存在し、200以上の様々な自治体や5社以上のデータ整備を行う企業により整備されたデータをクラウド上に集約し、データの品質検査や変換から公開までを一貫して行えるシステムを構築しています。
このシステムには、現在開発中のRe:Earth CMSというEukarya開発のOSSプロダクトが使用されています。バックエンドはGoで実装されています。SaaSとしては現在まだ正式リリースしていませんが、PLATEAU VIEWでは既に本番稼働の実績があります。
このCMSでは、PLATEAUの標準製品仕様書に基づき、様々な企業により作成されたCityGMLのデータをアップロードすることができるのですが、仕様書に基づいてフォルダの階層構造を持っていてファイル数が非常に多く、合計サイズも数GB、ものによっては数TBと巨大なため、zipファイルまたは7zファイルに圧縮してからアップロードし、その後クラウド上でそれらを展開し、GCS上にファイルを配置して公開・配信を行う必要がありました。
そんなわけで、そんな巨大なzip/7zファイルをクラウド上で展開できる仕組みを構築する必要が出てきたわけです。
初期のアーキテクチャ
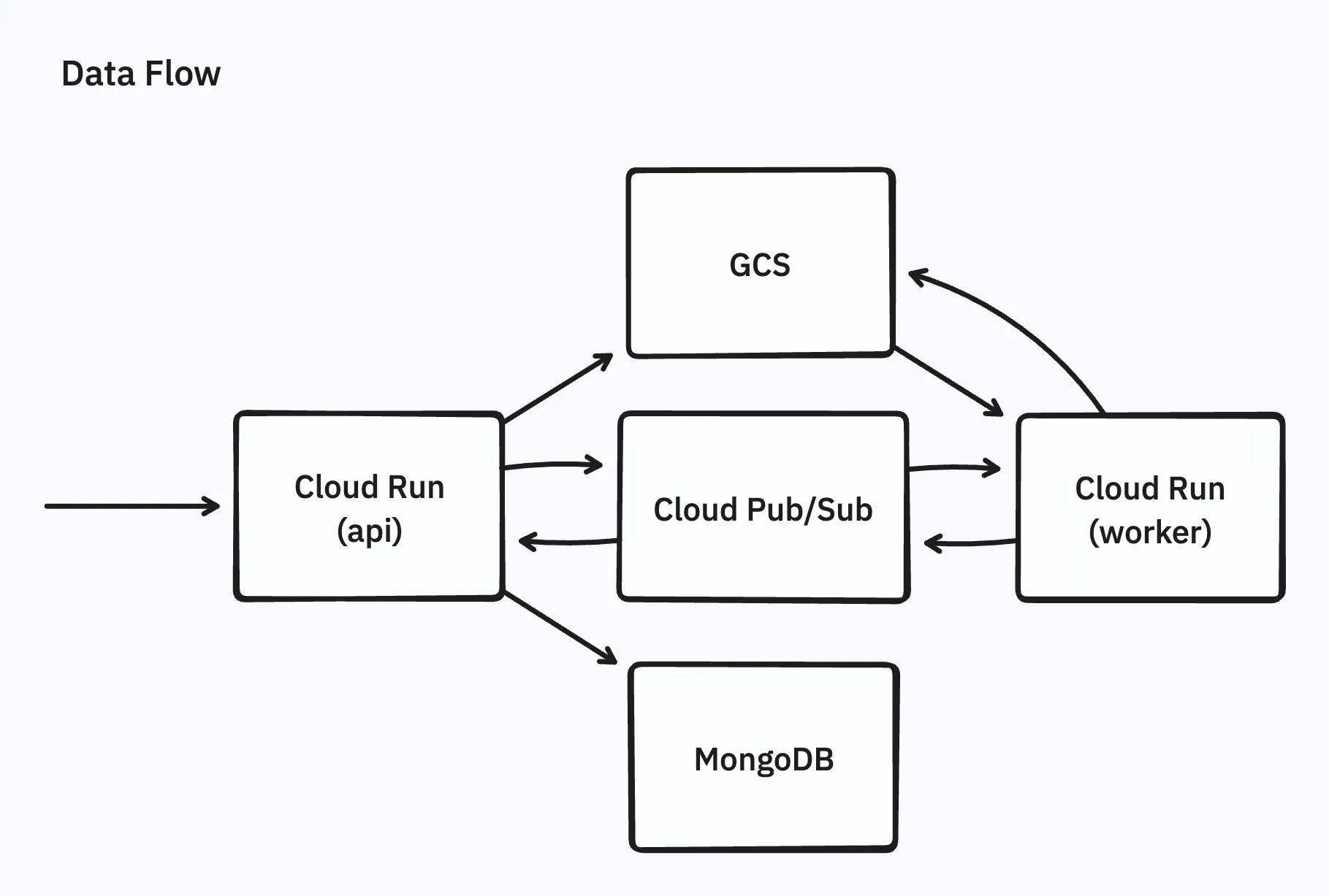
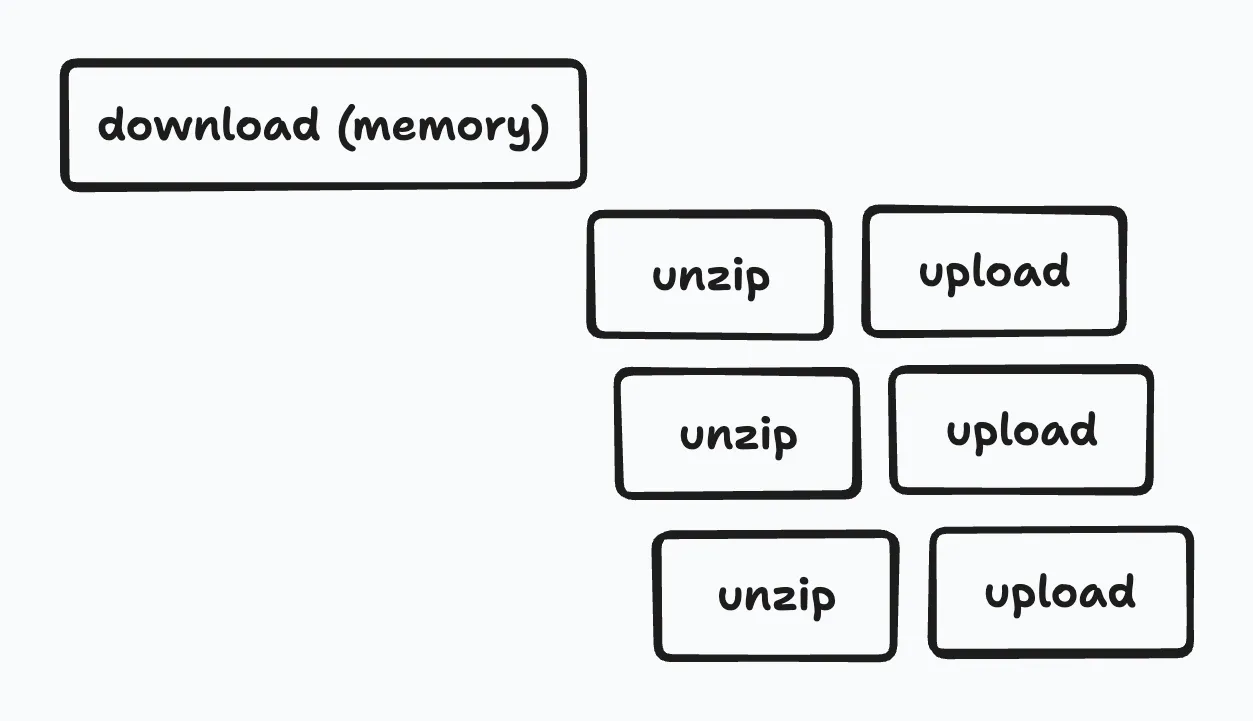
初期の実装はシンプルに、Webブラウザからapi(Cloud Runで動作するAPIサーバー)経由でアーカイブファイルをGCSにアップロードしたあと、ワーカーをCloud Runを用いて起動し、ワーカーでアーカイブファイルの内容をまるごとメモリに載せて展開し、展開されたファイルをGCSに並列アップロードするものでした。
この構成では以下の問題があり、要件を達成できていませんでした。
- zipファイルが大きすぎて、Cloud RunのAPIサーバーへのzipファイルアップロードでタイムアウト
- zipファイルが大きすぎて、ワーカーのメモリ使用量が不足(Goにおいてzipの展開は
io.ReaderAtを要求するため、zipファイルまるごとメモリに載せる必要あり) - zipファイルが大きすぎて、ワーカーの処理時間が非常に長くなりタイムアウト(数十時間かかることも)
このアーキテクチャでは、4GB程度のzipファイルを解凍するのが限界だったため、まずは「10GBのzipファイルを解凍できること」をマイルストーンとして改善に取り組みました。
WebブラウザからGCSへ直接アップロード
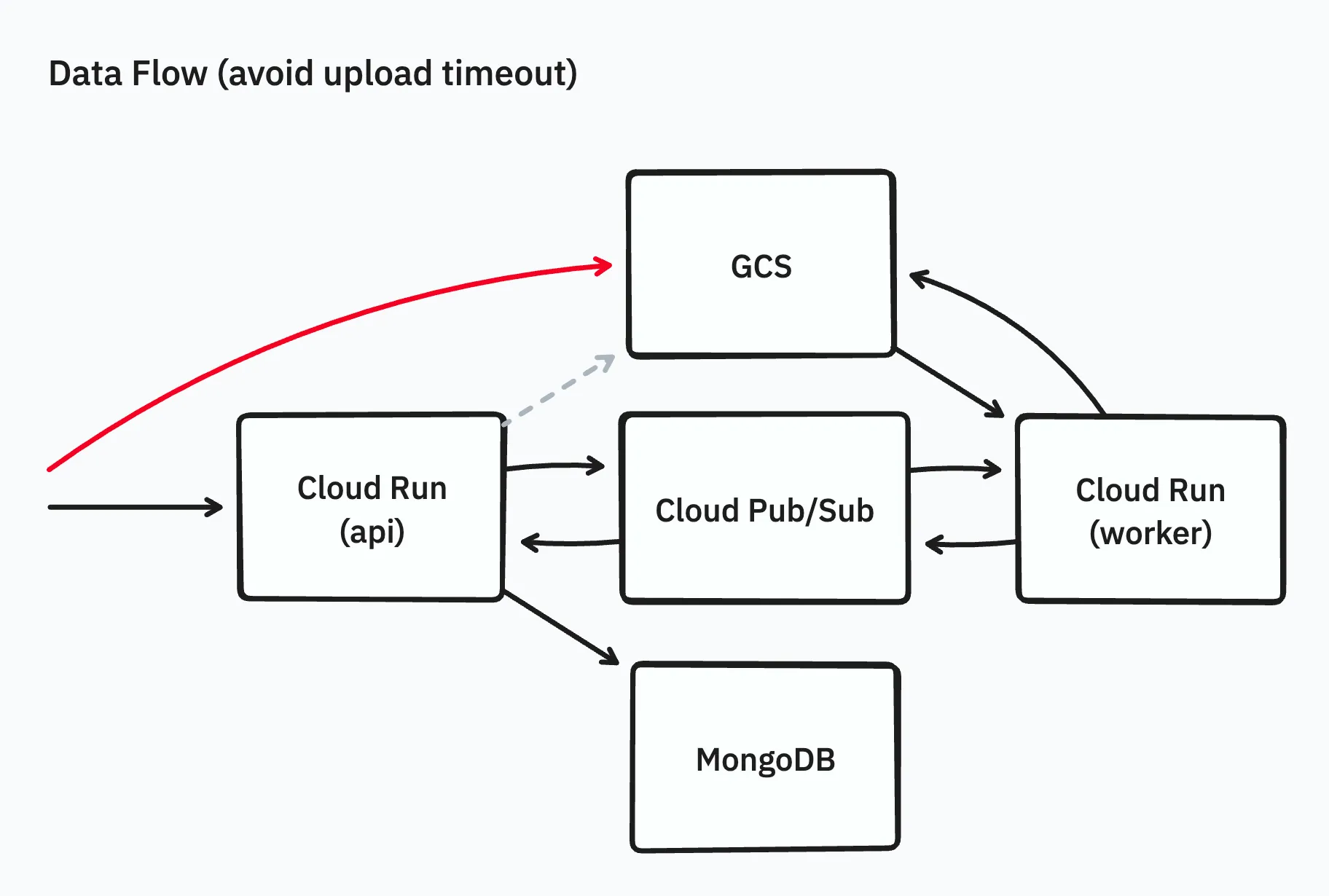
まず下準備として、フロントエンドがAPIサーバーに対して直接アーカイブファイルをアップロードすることをやめ、GCSから発行できる署名済みURLを用いて、Webブラウザから直接GCSにアップロードを行うようにしました。
これにより、Cloud Runのタイムアウトを回避できるようになり、副次的ですが余分なデータ転送も抑制できるようになり、大きなアーカイブファイルのGCSへのアップロードが可能になりました。
しかし、以下の問題が残っていました。
- ワーカーに大きなメモリが必要
- ワーカーの処理時間が長い
展開処理を再開可能にする
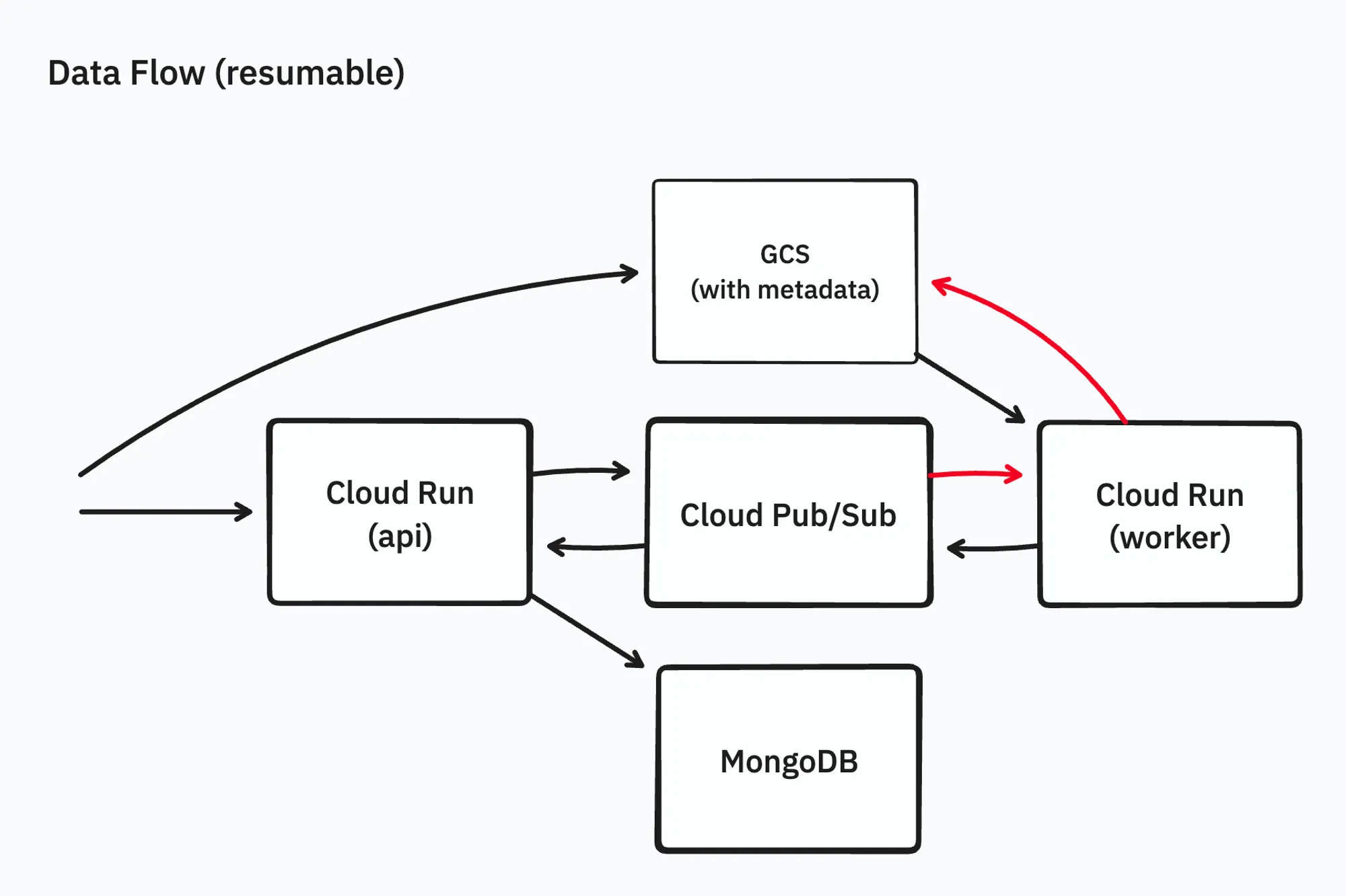

次に展開処理がworkerでタイムアウトになってしまう問題を回避するために、展開処理がタイムアウトなどで中断されても、あとから再開可能にすることを考えました。
GCS上のアーカイブファイルのメタデータに、どのファイルまで処理をしたかの情報を書き込むことで、展開処理を再開可能にします。また、どこまで処理したかの情報を単純化するために、アーカイブファイルの展開処理を直列化しました。
再開の処理自体はCloud Pub/Subのリトライ機能に委ね、これで10GBのzipファイルの展開ができるようになりました。
ただ、このアプローチには次の問題がありました。
- 途中から再開しても圧縮の形式によっては伸長は省略できず、シーク処理に時間がかかる
- ワーカーを並列実行したときに予期せぬ挙動が発生する
また、大きなアーカイブファイルは大量のファイルを含む場合が多く、ファイル数が多い場合に、APIサーバーが展開結果やファイル一覧をデータベースに保存する処理が、正常に動作しないことがわかりました。
ファイル一覧の内部表現の改善
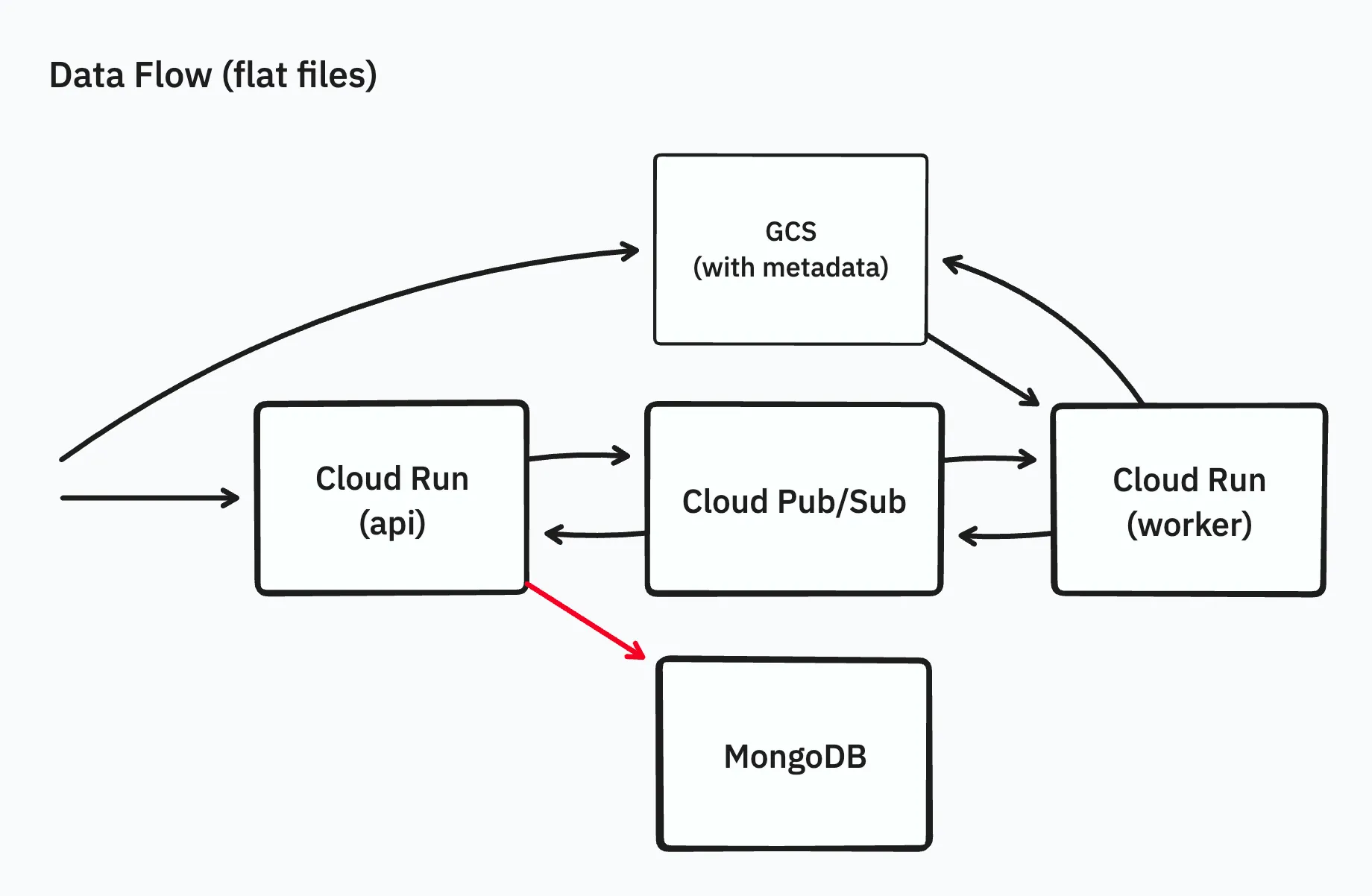
アーカイブファイル内のファイルの一覧を保存する処理が動かないのは、データベース内でファイルの一覧をツリー形式で1ドキュメントに保持していて、20万ファイルを超えるケースなどでMongoDBの1ドキュメント16MB制限にかかるようになっていたのが原因でした。
1000ファイルごとに1ドキュメントにまとめ、ツリーで保存することもやめてフラットな配列として保存するようにし、フロントエンドに対してレスポンスを返すタイミングでもともとのツリー形式に変換するようにしました。
また、フラットなリストをツリーに変換する処理自体も遅い問題があったので、アルゴリズムを最適化することで解決しました(ここでは主題から逸れるため割愛)。
これで 「10GBのzipファイルを展開する」というマイルストーンを完全に達成することができました。
とはいえ、メモリ上にアーカイブファイルの内容をすべてを展開するこの構成では、Cloud Runのメモリでは32GBが限界であり、「100GBのzipファイル展開」は達成できそうにありませんでした。
Cloud Build を使用して展開する
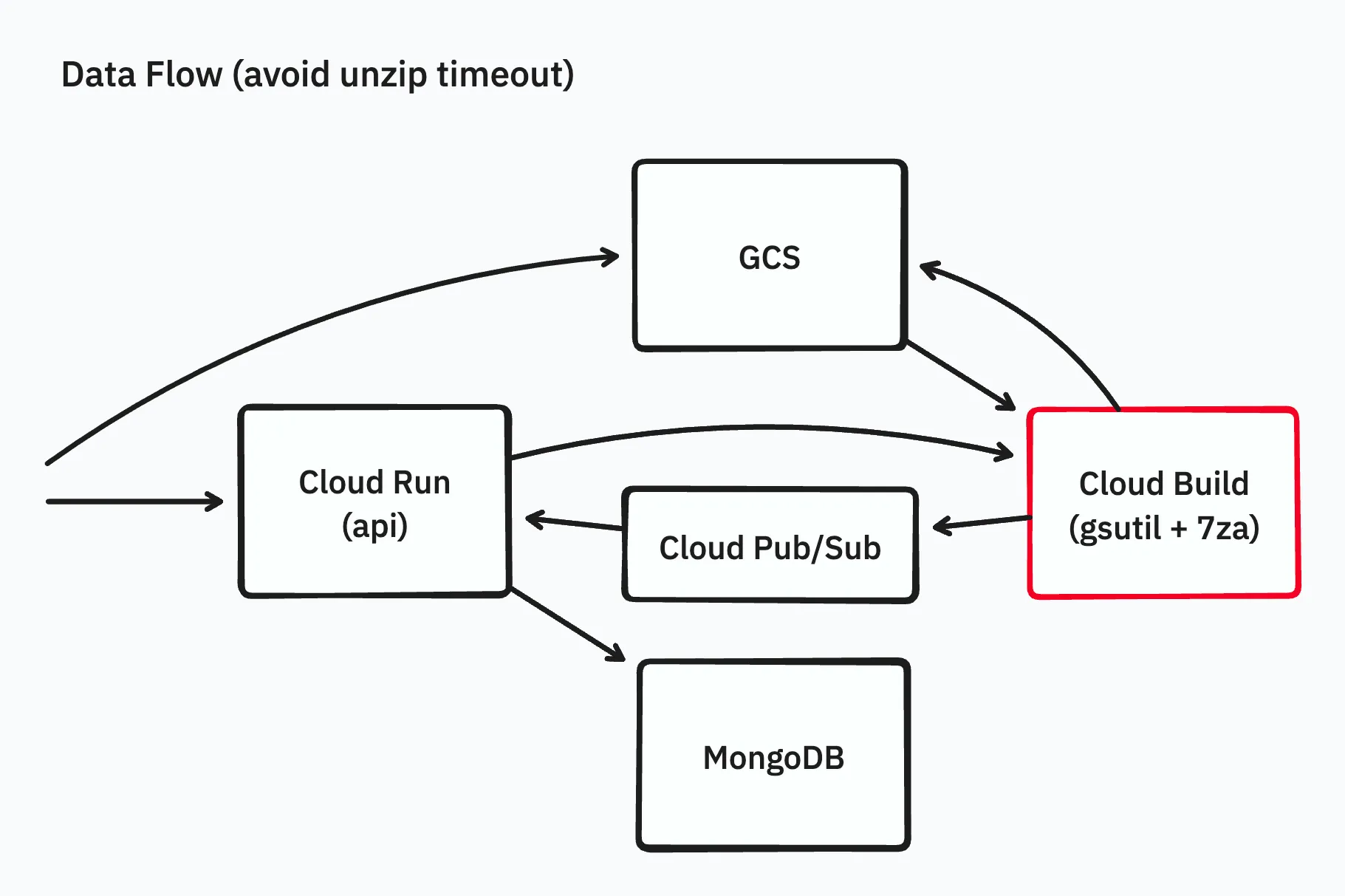
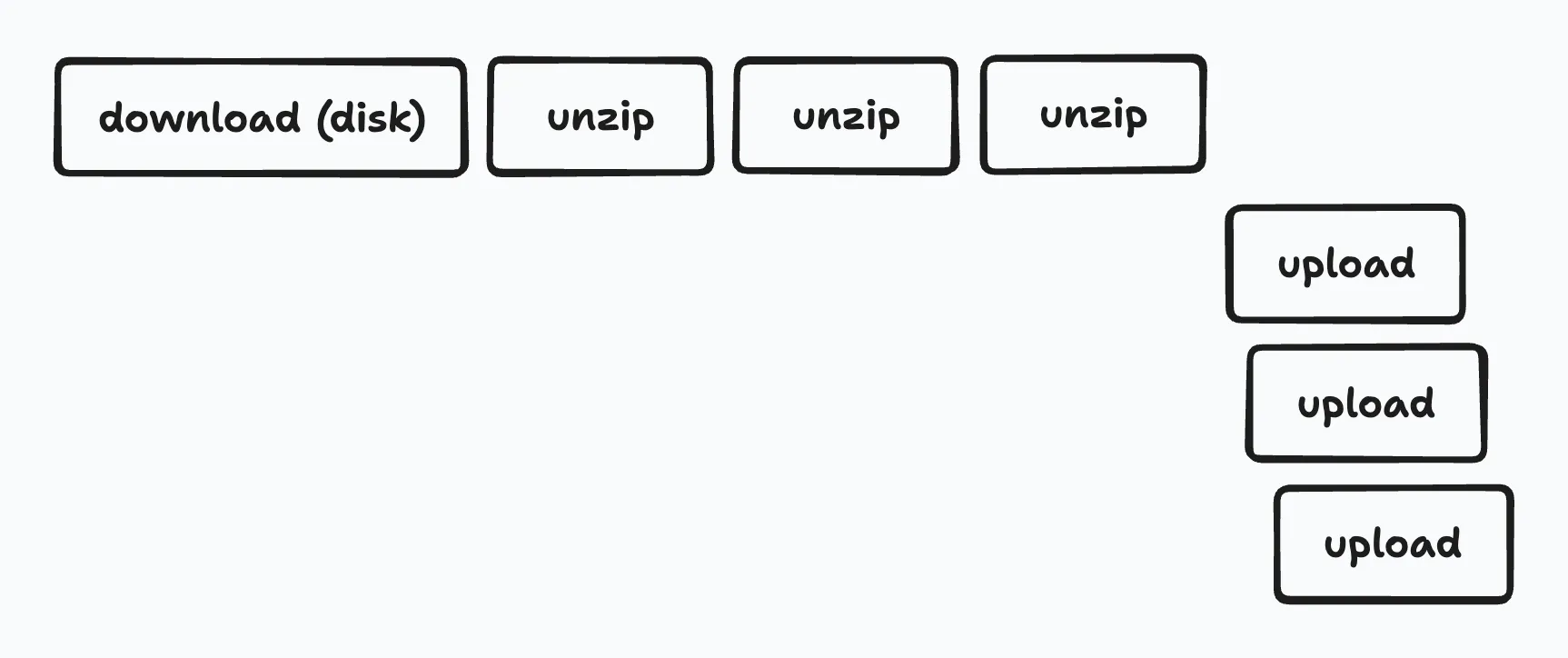
今回は問題を早期に解決したいということもあり、Cloud Runよりもタイムアウトが長く、任意のDockerイメージを簡単に動かして処理をさせることができるCloud Buildをワーカーの実行基盤として使うことにしました。Cloud Buildではタイムアウトを最長24時間に設定することができます。
また、このタイミングで処理内容を、gsutilおよびgcloud storageコマンドによるダウンロード・アップロードと7zaによる展開の組み合わせに変更しました。
この変更によってタイムアウトの問題を回避でき、処理自体は正常に終了するようになりました。しかし、gsutil/gcloud storageの並列化オプションでは処理時間が想定より長くなってしまうことがわかりました。
この問題が起きている原因について、以下のような仮説を立てて検証することにしました。
- gsutil/gcloud storageによるアップロードが正しく並列化できていない
- アップロードの順序によっては、プレフィックスに偏りがあると遅くなる
アップロードを並列化する
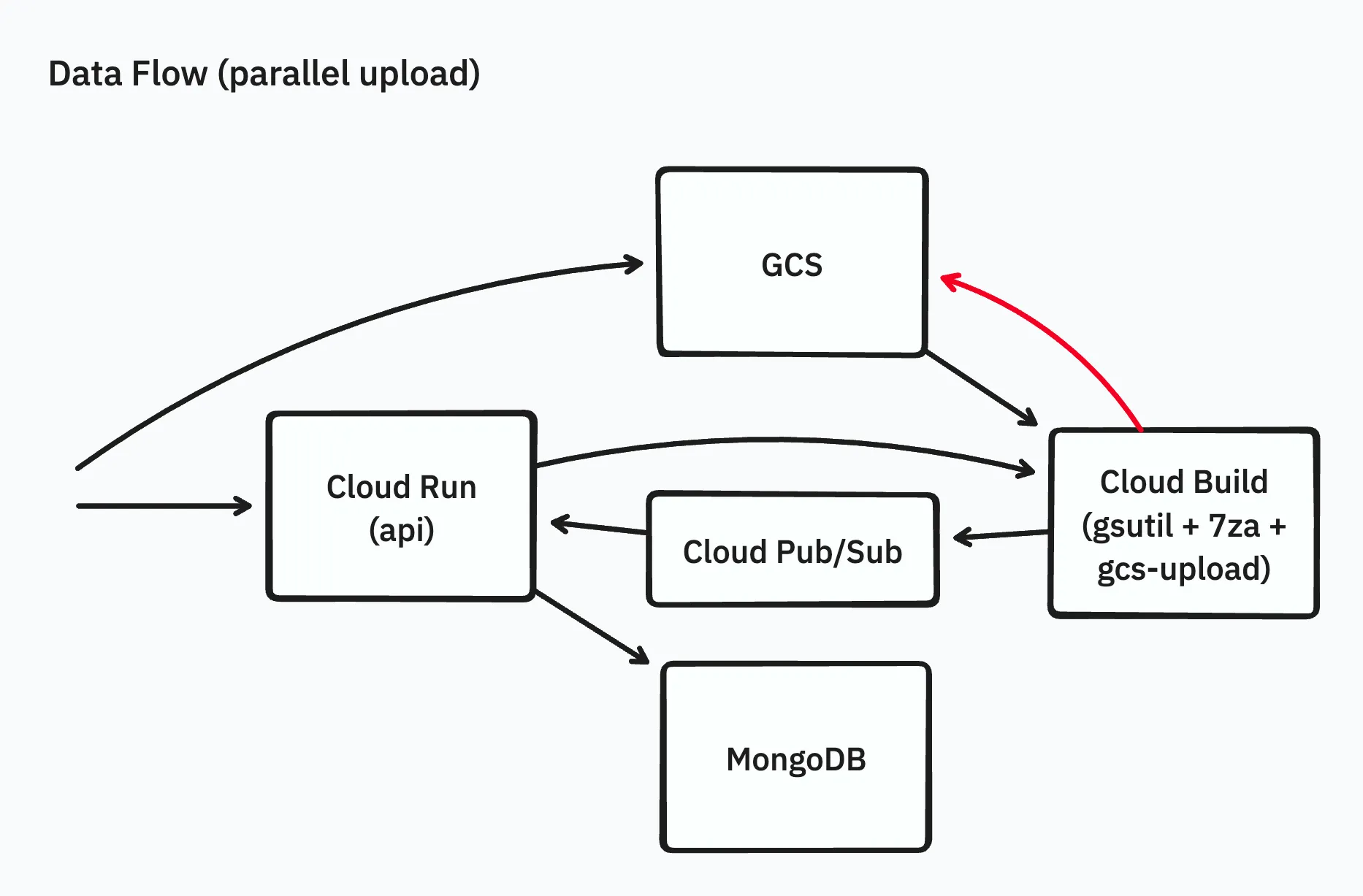
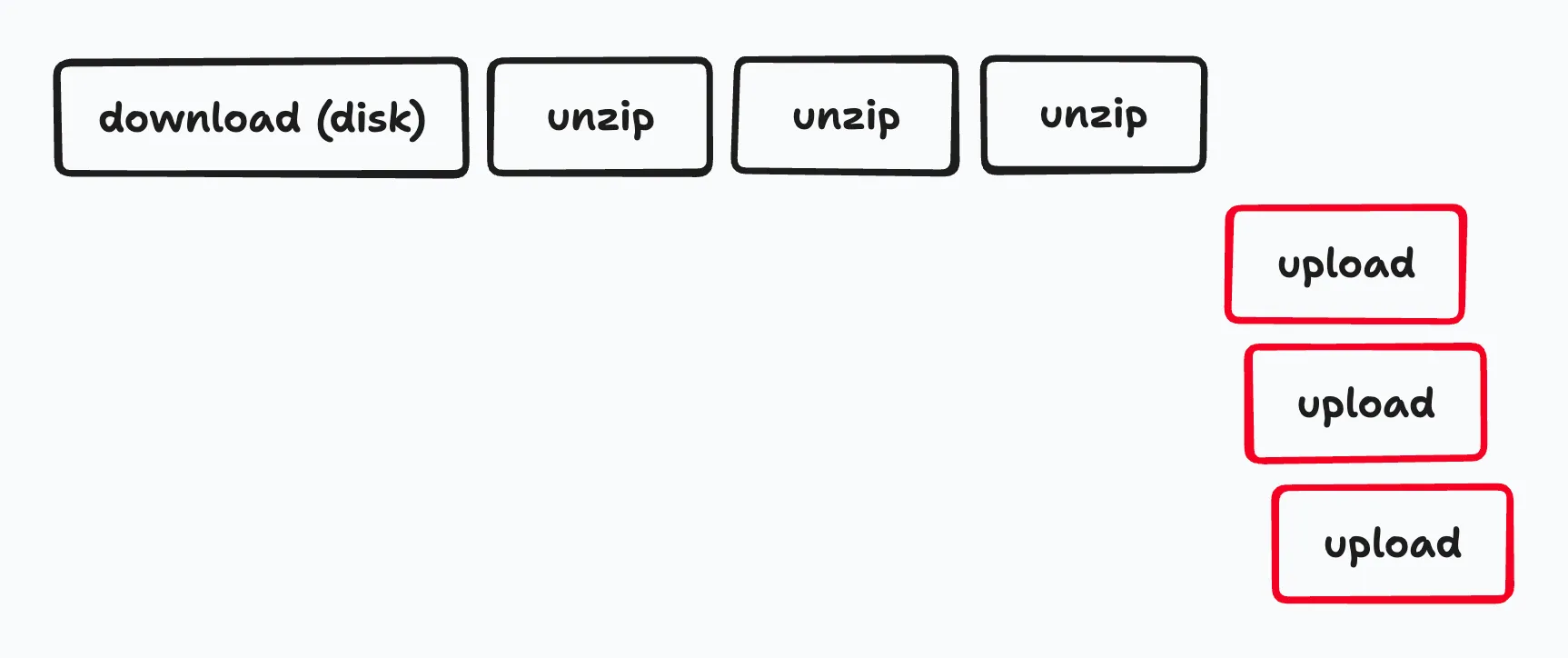
gsutil/gcloud storageのアップロードの部分を並列化するために、独自にGoでgcs-uploadというツールを実装し、実験してみました。以下はgcs-uploadのソースコードの抜粋です。
ctx := context.Background()
gcs, err := storage.NewClient(ctx)
if err != nil {
return fmt.Errorf("storage client: %w", err)
}
bucket := gcs.Bucket(dest.Hostname())
uploadBufPool := sync.Pool{
New: func() any {
return make([]byte, *bufSize)
},
}
var count atomic.Int64
uploadsStart := time.Now()
eg, ctx := errgroup.WithContext(ctx)
eg.SetLimit(*n)
listFileScanner := bufio.NewScanner(listFile)
for listFileScanner.Scan() {
f := listFileScanner.Text()
eg.Go(func() error {
select {
case <-ctx.Done():
return nil
default:
}
r, err := os.Open(filepath.Join(*dir, f))
if err != nil {
return fmt.Errorf("open upload file: %w", err)
}
defer r.Close()
name := path.Join(dest.Path[1:], filepath.ToSlash(f))
o := bucket.Object(name).Retryer(storage.WithPolicy(storage.RetryAlways))
w := o.NewWriter(ctx)
w.ChunkSize = int(*chunkSize)
defer w.Close()
buf := uploadBufPool.Get().([]byte)
defer uploadBufPool.Put(buf)
var start time.Time
if *verbose {
start = time.Now()
}
if _, err := io.CopyBuffer(w, r, buf); err != nil {
return fmt.Errorf("upload: %w", err)
}
if err := w.Close(); err != nil {
return fmt.Errorf("close writer: %w", err)
}
c := count.Add(1)
if *gcInterval > 0 && int(c)%*gcInterval == 0 {
runtime.GC()
}
if *verbose {
log.Printf("%7d: -> %s: %s", c, "gs://"+path.Join(o.BucketName(), o.ObjectName()), time.Now().Sub(start))
}
return nil
})
}
if err := eg.Wait(); err != nil {
return fmt.Errorf("uploads: %w", err)
}
このgcs-uploadを用いて並列でアップロードすると、gsutilと比べて処理時間が100倍高速になりました。具体的には、gsutilで27万ファイルのアップロードが48並列で976分かかっていたのが、48並列で9分となりました。
もしgsutilやgcloud storageを使ってGCSにファイルをアップロードをしている場合は、このように自ら並列アップロードする処理を書いてみると、大きく速度が向上する可能性があります。
GoでGCSへの並列アップロードを書く上でのちょっとしたTipsですが、 cloud.google.com/go/storageのWriterには内部バッファが既に存在するので、自分でバッファを用意する必要がないというのと、デフォルトでバッファが16MBあり、例えば1000並列でアップロードするとOOMしてしまうことがあるので気をつける必要があります。
なお、ファイルのアップロード順序によるホットスポットの問題があるという仮説については、アップロードするファイルの順序をランダムにシャッフルする機能を実装し実験しましたが、効果はありませんでした。
以上の検証により、並列アップロードの独自実装により高速化が見込めることがわかりました。
しかし、アップロード部分のみの改善を検証するために7zaで結果をディスクに展開する作りにしていましたが、実際のユースケースでは、展開後のサイズが1TBを超えてしまうような巨大なアーカイブファイルがあることがわかり、それらに対応するために構成を変える必要がありました。
展開とアップロードを並行処理する
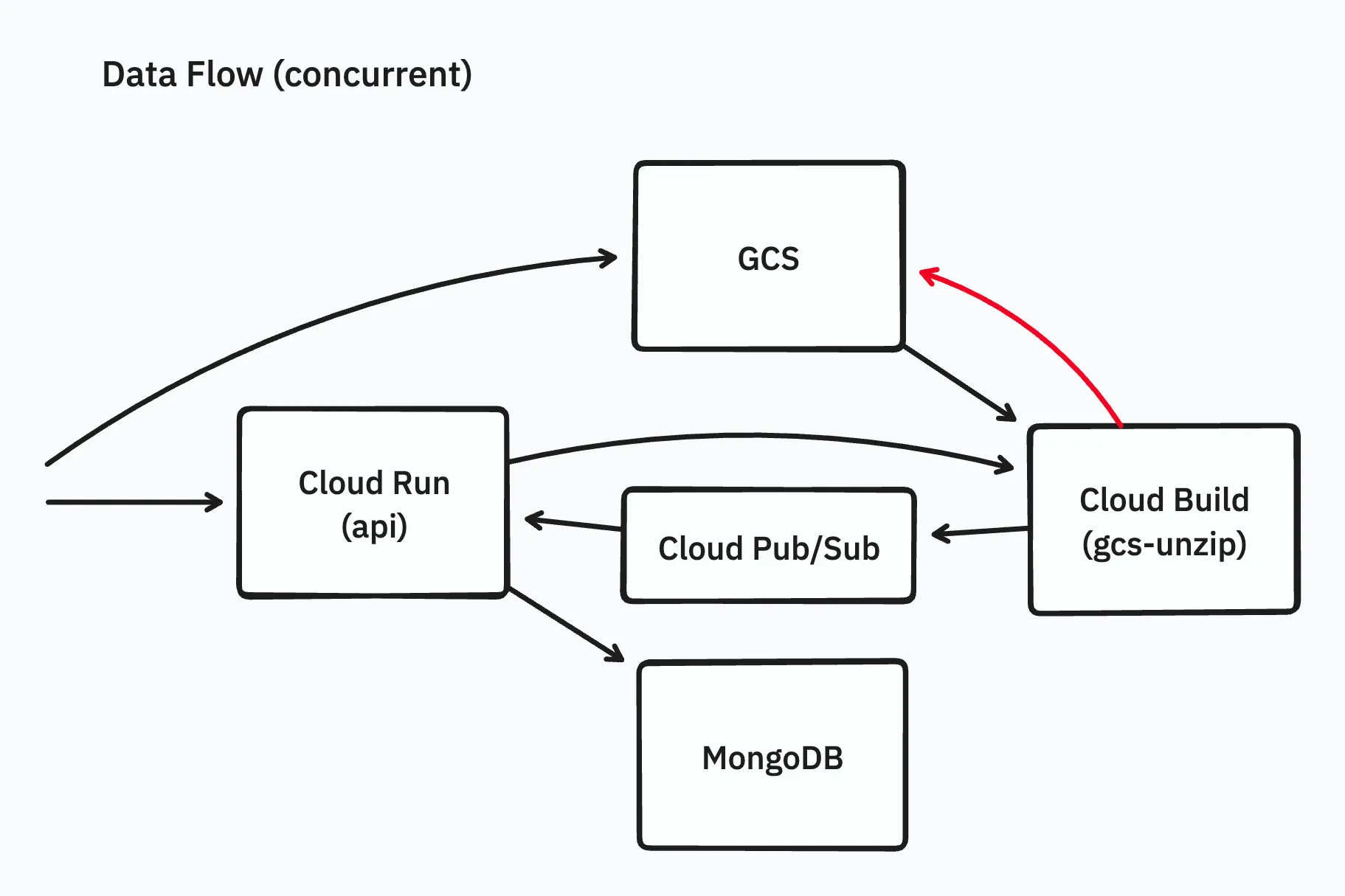
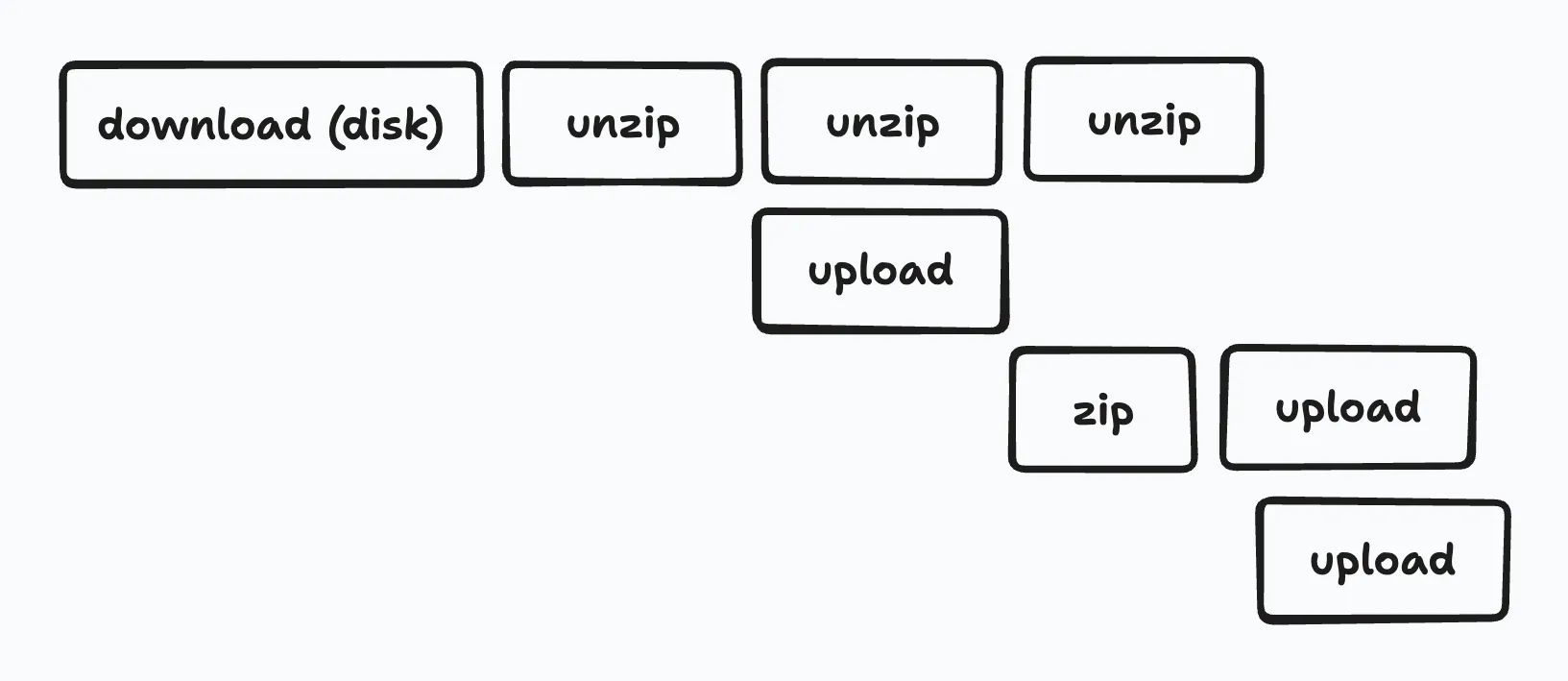
次に、展開に必要なディスクサイズを少なくするために、展開とアップロードを並行で処理できるツールを実装しました(gcs-unzip)。
展開されたファイルを1つずつアップロードし、アップロードが終わり次第ファイルを削除する作りにすることで、ディスクサイズの問題を回避しました。
ナイーブに実装すると並列アップロード時にディスクを使用しすぎてしまいますが、semaphoreを使うことで最小限の実装でディスク容量の制限を実現できました。
ところで、巨大なファイル群をGCSにアップロードする際には、ストレージ料金も気にする必要があります。
今回のユースケースにおいては、アーカイブファイル内には圧縮が効きやすいXMLファイルが多数含まれていました。
そこでストレージ料金を節約するため、特定の条件に合致したファイルについては、gzip圧縮した状態のままGCSにアップロードする機能も実装しました。
GCSではgzip圧縮した状態のままアップロードできる機能があり、ダウンロードの料金は変わりませんがストレージ料金は下がるので、今回のようなユースケースにおいては是非やっておくとよいでしょう。
https://cloud.google.com/storage/docs/transcoding?hl=ja
また、内部で使用しているsevenzipとxzのライブラリの高速化にも取り組み、プルリクエストを提出しましたが、現時点ではまだマージされていません。以下のxzのプルリクエストでは、処理を最適化して20%程度の高速化に成功しました。
https://github.com/ulikunitz/xz/pull/55
ここまでやって、Cloud Buildのストレージサイズを調整することで、マイルストーンであった100GBを大きく超えて、最終的には500GBのzipの展開にも成功しました。
得られた知見
- gsutilの並列化が適切に動いているかなど、既存ツールであっても自ら実装して速度を検証してみるのも大事
- GoでGCSのアップロードを並列化するときは、Writerのchunkサイズを気にする必要がある
- ダウンロードが少なく圧縮が効くケースではGCSのgzip Transcodingを検討してみる
- 普段使用しているツールやライブラリにも高速化の余地はある
今後の展望
Cloud Buildは、手軽に使えるなど利点もあるものの、本来はCI/CDに使うもので、zip/7zファイルの展開という目的外の利用をしているため、将来的にはCloud Run JobsまたはCloud Batchに移行していきたいです。
また、今の実装ではアーカイブファイルをまるまるディスクにダウンロードすることが必要なので、それをやめ、なるべくストリーム処理だけで中身のファイルを読み出せるように改善する事も考えられます。
また、展開してアップロード待ちのファイルをディスクに書き込むときにgzip圧縮するという方法も検討できます。これによりアップロードの並列度を向上させることができる可能性があります。
Eukaryaでは様々な職種で採用を行っています!OSSにコントリビュートしていただける皆様からの応募をお待ちしております!
Eukarya is hiring for various positions! We are looking forward to your application from everyone who can contribute to OSS!
Eukaryaは、Re:Earthと呼ばれるWebGISのSaaSの開発運営・研究開発を行っています。Web上で3Dを含むGIS(地図アプリの公開、データ管理、データ変換等)に関するあらゆる業務を完結できることを目指しています。ソースコードはほとんどOSSとしてGitHubで公開されています。
➔ Re:Earth / ➔ Eukarya / ➔ note / ➔ GitHub
Eukarya is developing and operating a WebGIS SaaS called Re:Earth. We aim to complete all GIS-related tasks including 3D (such as publishing map applications, data management, and data conversion) on the web. Most of the source code is published on GitHub as OSS.