Building a MongoDB cluster on Google Cloud for non-disruptive rolling updates
2025-04-11

Hello, this is Keke from the SRE team at Eukarya Inc.
Our company provides Re:Earth CMS as the backend for "LINKS Veda," a data infrastructure platform for Project LINKS, a cross-domain DX promotion project by the Ministry of Land, Infrastructure, Transport and Tourism of Japan. Re:Earth CMS uses MongoDB as its database, and we recently built a self-hosted MongoDB replica set on Google Cloud. The system needed to be highly reliable and have minimal operational costs. In this article, I'll introduce the system we built using Stateful Managed Instance Groups (MIG), as there weren't many reference cases available.
Why Self-Hosted?
At our company, we actively adopt serverless technologies like Cloud Run and managed services like MongoDB Atlas for infrastructure construction and operation. This allows us to minimize economic and operational costs while enabling engineers to focus on feature development and business logic. As our service has grown, a small team, including our CTO, has efficiently handled infrastructure management.
However, the reason we had to choose self-hosting this time was that practical managed services for our technology stack, including MongoDB Atlas, were not included in the ISMAP Cloud Service List certified by the Japanese government.
Amazon Web Services (AWS), which is certified, does have AWS DocumentDB that's compatible with MongoDB. However, this is limited to internal network access (access from within the same network space), requiring VPN connections or reverse proxies to access services hosted on Cloud Run. This would lead to a multi-cloud configuration or the need for VPN connectors, increasing system complexity. For our small team, operating such a configuration was not realistic.
Furthermore, according to MongoDB Atlas's report, as of November 2023, AWS DocumentDB's compatibility with MongoDB was only about 34%. For these reasons, we wanted to avoid application constraints or significant changes that might be caused by AWS DocumentDB's compatibility rate. We had similar concerns about Microsoft Azure's Azure Cosmos DB for MongoDB.
Given these reasons, although self-operating a MongoDB replica set comes with an operational burden, after comprehensive evaluation, we determined that self-hosting on Google Cloud was the optimal choice. We aimed to build a system with maximum availability and reliability within our limited resources.
What are Stateful Managed Instance Groups (MIG)?
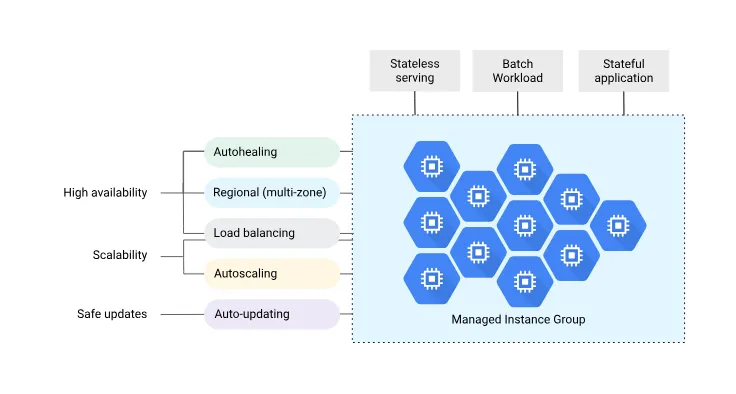
Managed Instance Groups (MIG) is a Google Cloud service that allows you to manage multiple instances with the same configuration as a group. AWS provides a similar functionality called Auto Scaling Group.
Production servers typically have a high-availability (HA) configuration, usually consisting of two or more instances. Rather than building multiple instances individually, using MIG provides the following advantages:
- Auto-scaling: Automatically increase or decrease the number of instances according to load.
- Auto-healing: Automatically restart or recreate instances when health checks fail.
- Continuous delivery: Manage configurations with instance templates and apply deployment methods such as automatic rolling updates when changes occur.
- High availability: Automatically launch new instances when failures occur to ensure service continuity.
- Topology specification: Specify and operate with a particular topology, such as evenly deploying multiple instances across multiple zones.
When building instances with identical configurations, using MIG can automate many operational management tasks, improving system reliability and efficiency.
However, for stateful applications like MongoDB, (normal) MIG is not sufficient. For example, when configuring a MongoDB replica set, the following requirements must be met when a node (instance) is recreated:
- The persistent disk attached to the node before recreation must be attached to the new node.
- It must be recreated with the same instance name (internal DNS name) so other nodes can still resolve it after recreation.
- Automatic failover must occur when the primary node goes down, allowing continuous read and write operations.
This is where Stateful MIG comes in. Stateful MIG provides various functions to support stateful workloads in addition to the normal MIG functionality. Stateful MIG consists of the following elements:
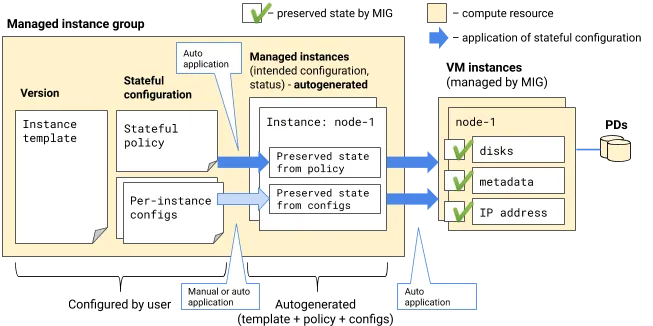
Specifically, it allows for persistent disk management, assignment of fixed instance names and internal IP addresses, and retention of instance-specific configurations. These features enable stateful applications like MongoDB to maintain data consistency and availability while taking advantage of MIG benefits. For those familiar with Kubernetes, you can think of MIG as corresponding to Deployments and Stateful MIG as corresponding to StatefulSets.
Additionally, MIG includes (regular) MIG that deploys to a single zone and regional MIG that deploys to a single region. Since we often choose region (multi-zone) configurations for high availability, we selected regional MIG this time. Note that even with regional MIG, you can deploy to a single zone by specifying SINGLE_ZONE for the topology, but you cannot change the zone afterward.
For detailed mechanisms of Stateful MIG, please refer to the official documentation "How Stateful MIGs work".
Regional MIG Updates Do Not Occur Synchronously Across Zones
Adopting a region (multi-zone) configuration maintains availability even if one zone fails, making it a desirable configuration, especially for applications requiring high availability. Regional MIG meets this requirement, but caution is needed when the number of instances is small, particularly when the number of instances is less than the number of zones.
For updates with fixed instance names or Stateful MIG changes, since the same hostname or disk cannot exist simultaneously, the number of instances that can be added during updates (surge count) must always be set to 0, and the maximum unavailable instance count must be set to at least the number of zones.
For example, if you have one instance in each of the three zones, the maximum unavailable instance count should be 3 (the same as the number of zones) or more. When ensuring availability during updates, you would ideally want to update one instance at a time in each zone as follows:
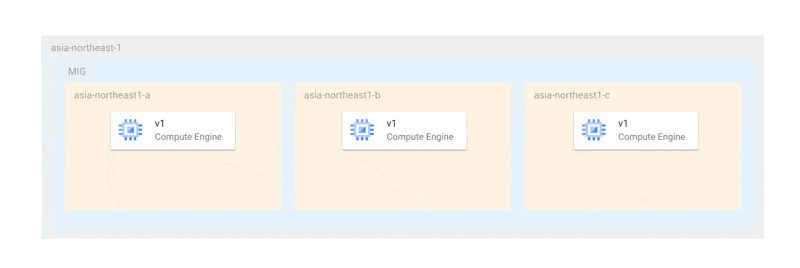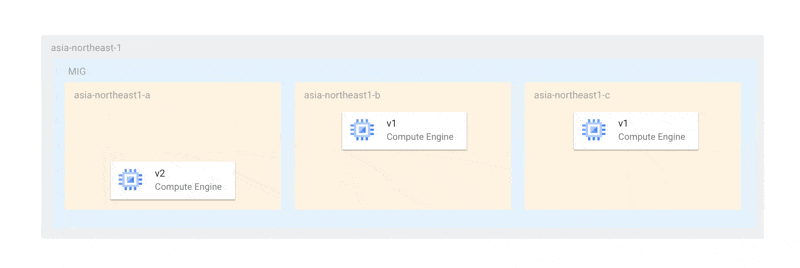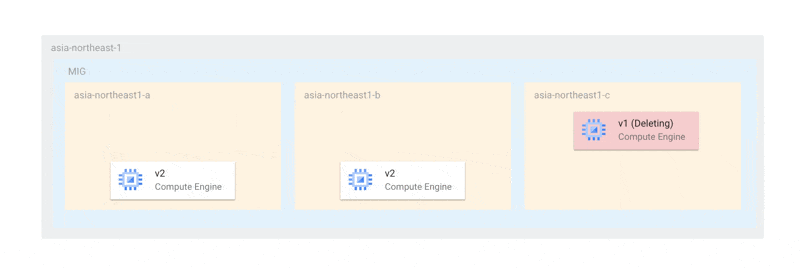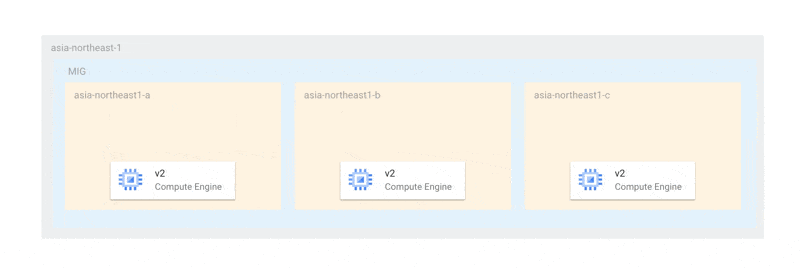
With this method, at least two instances would always be running to elect a primary, ensuring that availability is never compromised during updates. However, under the current specifications, updates occur simultaneously across all zones as follows:
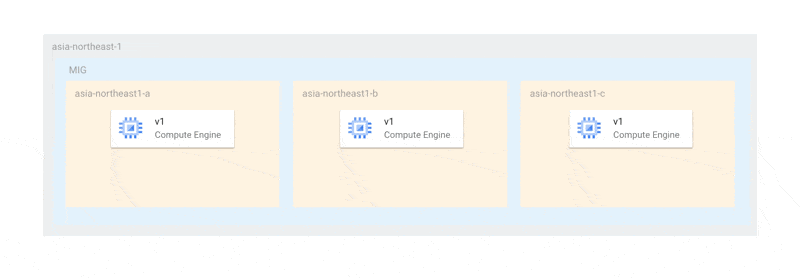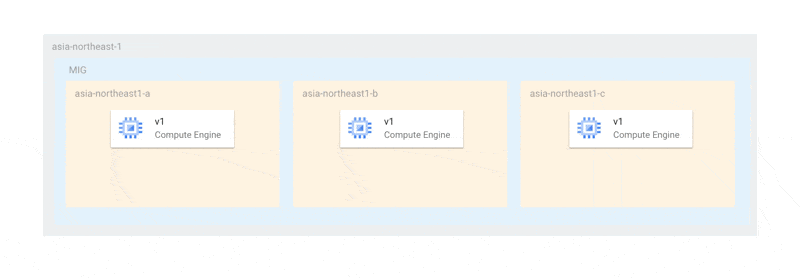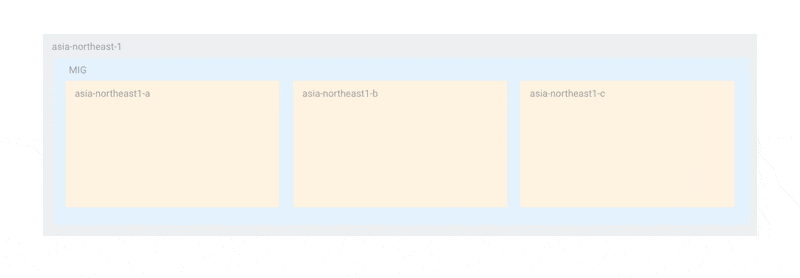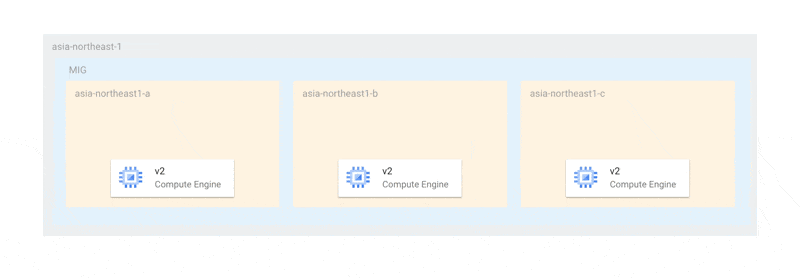
This is due to the restriction that the maximum unavailable instance count must be at least the number of zones. Therefore, in cases like ours, where there is only one instance per zone, in the worst case, all instances could stop simultaneously. Even if a complete outage is avoided, if there aren't enough nodes for MongoDB primary election, the replica set may become dysfunctional.
There are several ways to avoid this problem:
- Use single-zone MIG (single-zone configuration)
- Specify
SINGLE_ZONEfor topology and set the maximum unavailable instance count to less than the number of zones (also single-region configuration) - Increase the number of instances to meet the primary election requirement nodes and have at least 2 instances in each zone
- Build a replica set that doesn't depend on instance names by introducing Hashicorp Consul or load balancers
All of these methods either reduce reliability or increase economic and operational costs, making them impractical for us.
Utilizing MongoDB Arbiter for Region Configuration
MongoDB (Replica Set) Arbiter is a lightweight node that assists in electing the primary node within a replica set. The Arbiter itself doesn't store data; it only participates in primary election voting. This allows it to consume very few resources while enhancing availability and keeping costs down. It's used to ensure an odd number of nodes to smooth the primary election process.
Given the challenges mentioned earlier, we currently have the following configuration using Arbiters:
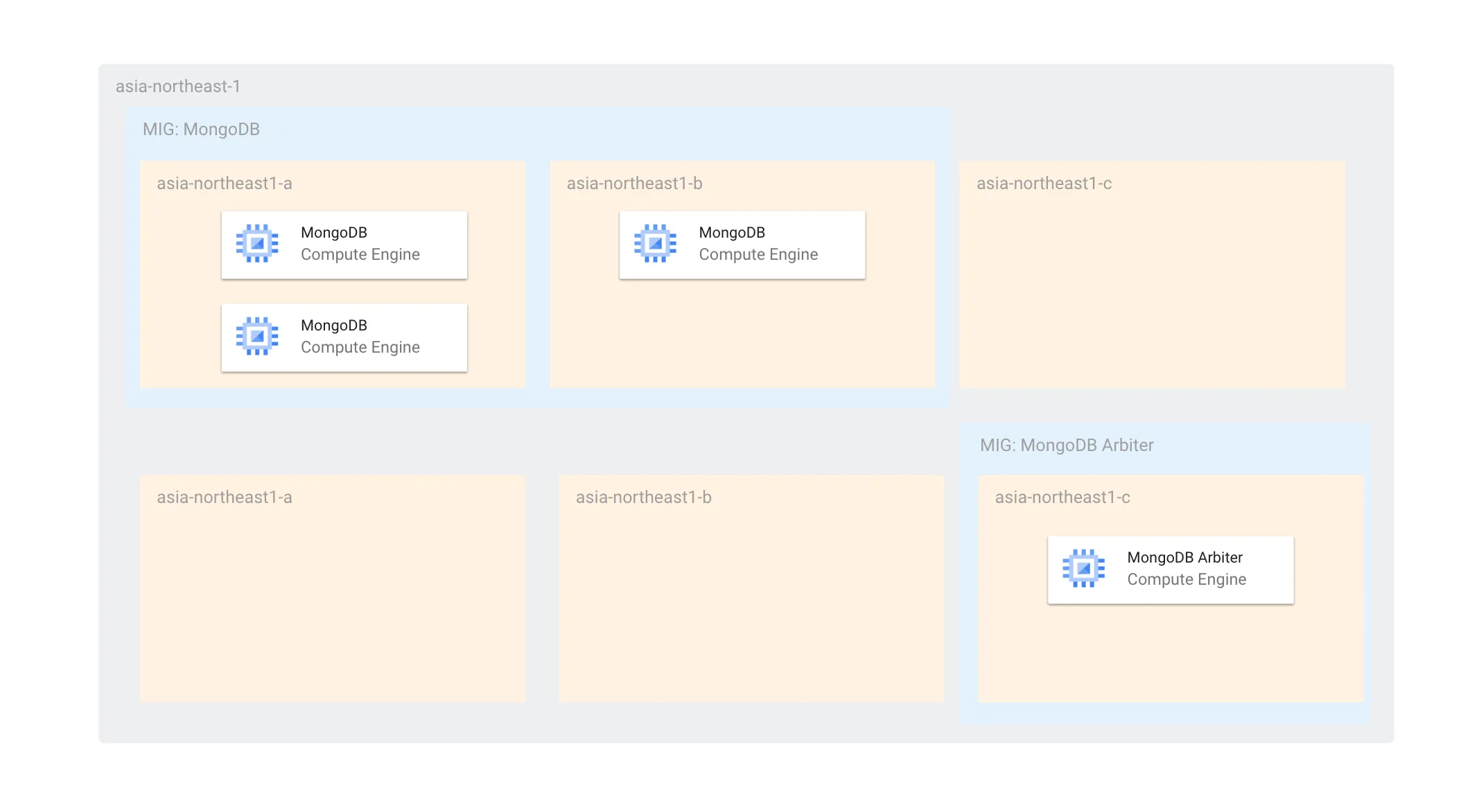
With Arbiters included, the number of MongoDB nodes per zone is 2 (more than 1), so during updates, a maximum of 2 nodes will be offline simultaneously, still allowing primary election. Also, since MongoDB's MIG is independent of Arbiter updates, even if all Arbiters are stopped, the MongoDB instances alone can sufficiently conduct primary elections.
The configuration is also resilient to single-zone failures. During a failure, the Arbiter and the remaining MongoDB can elect a primary. By setting the MIG topology to EVEN, we ensure that instances are not concentrated in a single zone.
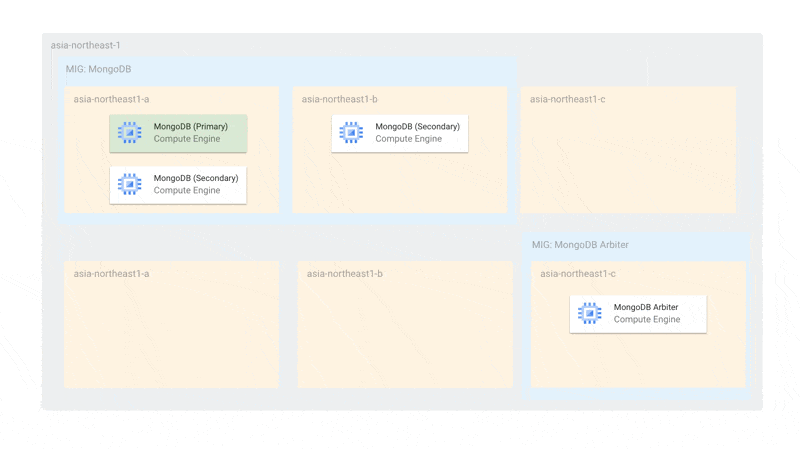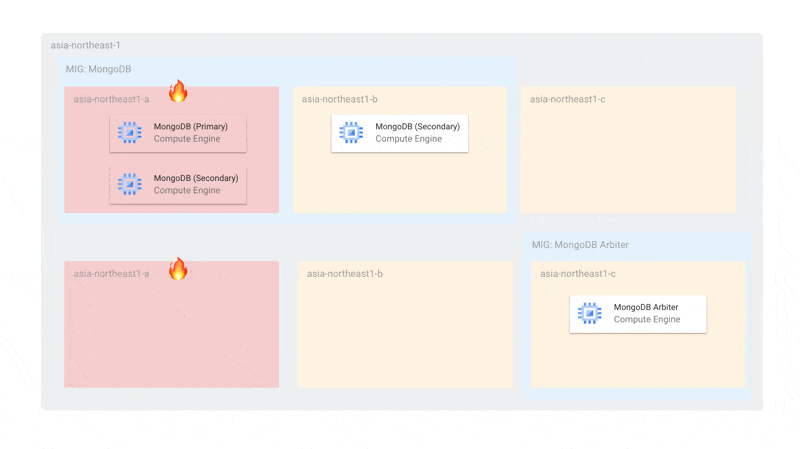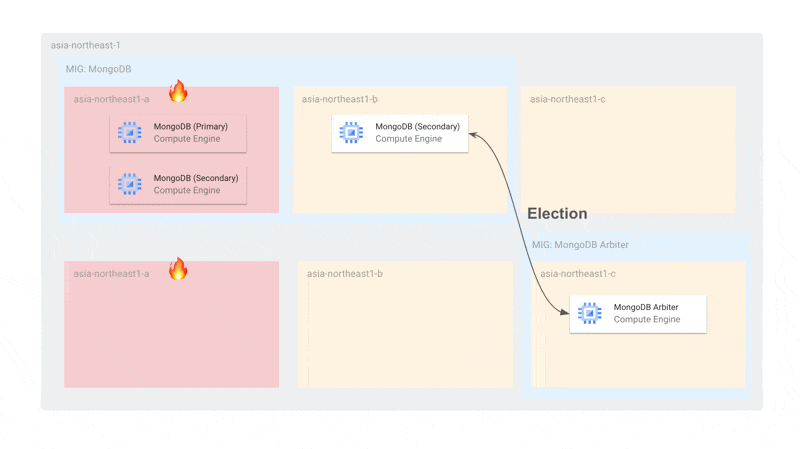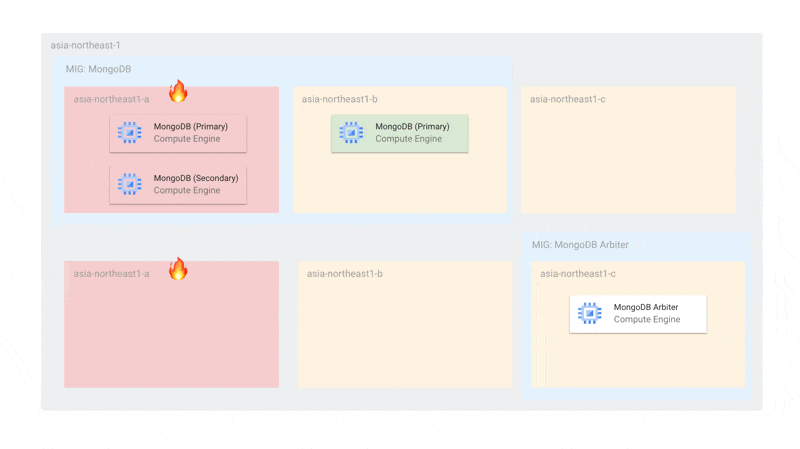
We separate the zones used for MongoDB and MongoDB Arbiter because if an Arbiter were scheduled in a zone with two MongoDB instances and that zone failed, primary election would become impossible. We separate zones to ensure that Arbiters and MongoDB don't exist in the same zone.
For authentication between nodes, we use keyfile authentication, and for monitoring, we use Google Cloud's Ops Agent. However, I'll omit details beyond MIG for now and introduce them on another occasion.
Creating Stateful MIG
We use Terraform for resource management, allowing us to manage infrastructure as code. Here's an example of our Terraform declaration:
Copy
resource "google_compute_region_instance_group_manager" "mongodb" {
base_instance_name = "mongodb"
name = "mongodb"
distribution_policy_zones = ["asia-northeast1-a", "asia-northeast1-b", "asia-northeast1-c"]
region = "asia-northeast1"
target_size = 3
# Auto-healing
auto_healing_policies {
initial_delay_sec = 90 # seconds
health_check = google_compute_health_check.mongodb.id
}
named_port {
name = "mongodb"
port = 27017
}
# Persistent disk
stateful_disk {
device_name = "mongodb-0"
delete_rule = "NEVER"
}
version {
instance_template = google_compute_instance_template.mongodb.self_link_unique
}
update_policy {
instance_redistribution_type = "NONE"
max_surge_fixed = 0
max_unavailable_fixed = 2
minimal_action = "REFRESH"
most_disruptive_allowed_action = "REPLACE"
replacement_method = "RECREATE"
type = "PROACTIVE"
}
}
Here are the key configuration points:
stateful_disk: Specifies a persistent disk. With Stateful MIG, when an instance is recreated, the disk that was attached before recreation is reattached.- This setting creates a Stateful MIG rather than a normal MIG. Similarly, settings like
stateful_internal_ipfor fixing private IP also create a Stateful MIG.
- This setting creates a Stateful MIG rather than a normal MIG. Similarly, settings like
update_policy: This will be introduced in the next section.
Other configuration items are the same as normal MIG. MongoDB Arbiter is declared similarly, but since Arbiters don't store data, no persistent disk is attached.
Update Policy
The update policy is a configuration that defines how instances are updated.
The main configuration items are as follows:
instance_redistribution_type: A Regional MIG-specific setting that specifies the redistribution method to correct instance imbalance between zones. For Stateful MIG, since instances need to maintain their state and cannot move to different zones, onlyNONEcan be specified.max_unavailable_fixed: The maximum number of offline instances, which must be at least the number of zones.replacement_method: Must be set toRECREATEto maintain instance names (internal DNS names) and stateful configurations. This is because multiple instances with the same hostname cannot coexist.- For the same reason,
max_surge_fixedmust be0, andmax_unavailable_fixedmust be at least the number of zones.
- For the same reason,
type: Specifies how instances are updated when the instance template is updated. We've chosenPROACTIVE(automatic) to ensure that instance template updates are always reflected.
With this configuration, updates can be applied automatically without compromising availability, even for updates involving recreation, while preserving instance names. The maximum number of offline instances is set to 2, which is the number of zones, ensuring that at least one MongoDB is always running.
Container Optimized OS (COS) Can Run Container’s Monitoring is Challenging
Google Cloud provides Container-Optimized OS (COS), a container runtime environment similar to Fedora CoreOS, based on Chromium OS, allowing easy container execution on GCE. This enables the simple deployment of, for example, MongoDB from Docker Hub on GCE.
However, we faced several challenges in monitoring and metric management during the operational phase.
A particular issue was that Google Cloud Ops Agent is not supported on COS, making it very difficult to monitor hosted applications.
While logs can be obtained using Cloud Logging, getting detailed information such as MongoDB-specific metrics (e.g., collection count, replication lag) requires additional work. Methods such as using MongoDB Exporter or OpenTelemetry Agent and integrating with Cloud Monitoring are available. However, this would require introducing Google Cloud's Managed Service for Prometheus and collecting and visualizing custom metrics, potentially increasing operational overhead.
While COS's strength lies in its simplicity, it incurs additional costs for operational management tasks like monitoring and metric collection. Therefore, we ultimately switched to running MongoDB directly as a binary on GCE VM instances.
Currently, images are created using Hashicorp Packer, which implements Infrastructure as Code (Images as Code). This enables efficient monitoring and operation using Google Cloud's native monitoring tools in a reproducible manner.
Conclusion
When building a MongoDB replica set on Google Cloud, we adopted Stateful Managed Instance Groups (MIG) instead of regular MIG. This allowed us to maintain persistent disks, instance names, and internal IPs, ensuring the stability of the MongoDB replica set while leveraging MIG's rolling update functionality to continue releasing changes without downtime.
In regional MIG updates, if we could allow the maximum unavailable instance count to be less than the number of zones while maintaining instance names (internal hostnames), we could potentially perform updates automatically without downtime. However, this can't be achieved with the current specifications, and it's a feature we'd really like to see implemented.
Our company develops and provides services like WebGIS, and while we often discuss graphical content and topics, we also focus on infrastructure and SRE to support highly reliable and robust services. There are still challenges with our current configuration, but we aim to continue working toward further automation and high availability.
Eukaryaでは様々な職種で採用を行っています!OSSにコントリビュートしていただける皆様からの応募をお待ちしております!
Eukarya is hiring for various positions! We are looking forward to your application from everyone who can contribute to OSS!
Eukaryaは、Re:Earthと呼ばれるWebGISのSaaSの開発運営・研究開発を行っています。Web上で3Dを含むGIS(地図アプリの公開、データ管理、データ変換等)に関するあらゆる業務を完結できることを目指しています。ソースコードはほとんどOSSとしてGitHubで公開されています。
➔ Re:Earth / ➔ Eukarya / ➔ note / ➔ GitHub
Eukarya is developing and operating a WebGIS SaaS called Re:Earth. We aim to complete all GIS-related tasks including 3D (such as publishing map applications, data management, and data conversion) on the web. Most of the source code is published on GitHub as OSS.