Decompress a huge 100GB zip file on GCS with Go
2024-06-25

Introduction
Many web applications and cloud services allow file uploads, but few automatically extract and display the contents of uploaded zip files. We set out to create a system on Google Cloud that could:
- Accept uploaded zip files
- Automatically extract their contents
- Store the extracted files on Google Cloud Storage (GCS)
A key challenge was ensuring the system could handle zip files as large as 100GB. To address this, we developed a production-level system in Go capable of automatically extracting 100GB zip/7z files uploaded to GCS.
This Post outlines the technology behind our solution.
Background
Project PLATEAU, led by Japan's Ministry of Land, Infrastructure, Transport and Tourism (MLIT), aims to create open data 3D city models nationwide. As part of this initiative, Eukarya developed and operates PLATEAU VIEW, which includes:
- Data visualization capabilities
- A cloud-based data management platform (CMS) that:
- Aggregates data from over 200 municipalities and 5+ companies
- Enables end-to-end data processing (quality inspection, conversion, publication)
Key features:
- Uses Re:Earth CMS, developed by Eukarya with a Go backend
- Allows users to upload CityGML data adhering to PLATEAU specifications
- Handles large files (several to tens of gigabytes) with complex folder structures
- Requires uploading compressed zip/7z files
- Extracts files on the cloud and places them on Google Cloud Storage (GCS) for public distribution
To meet these requirements, we developed a system capable of extracting large zip/7z files in the cloud environment.
Initial Architecture
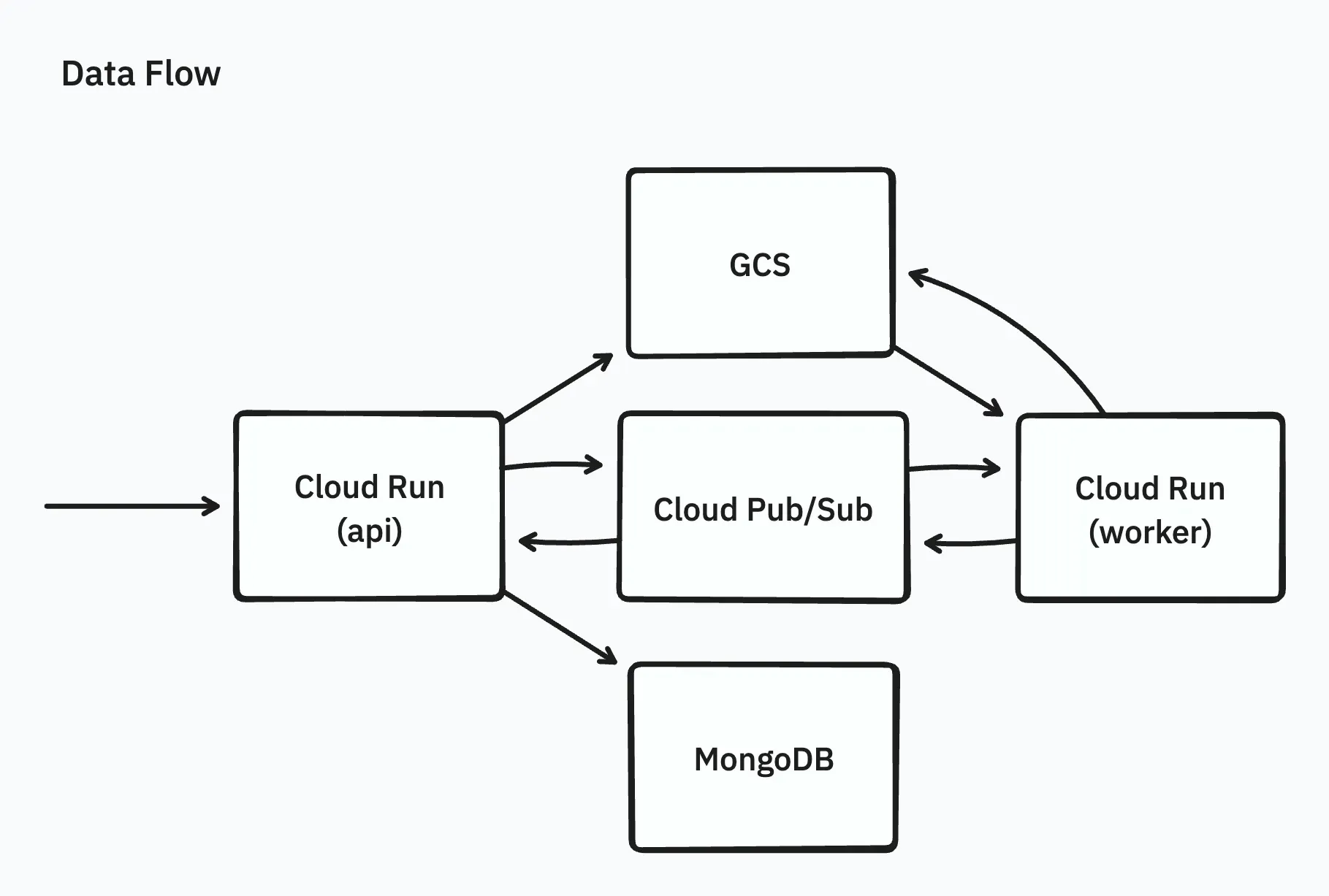
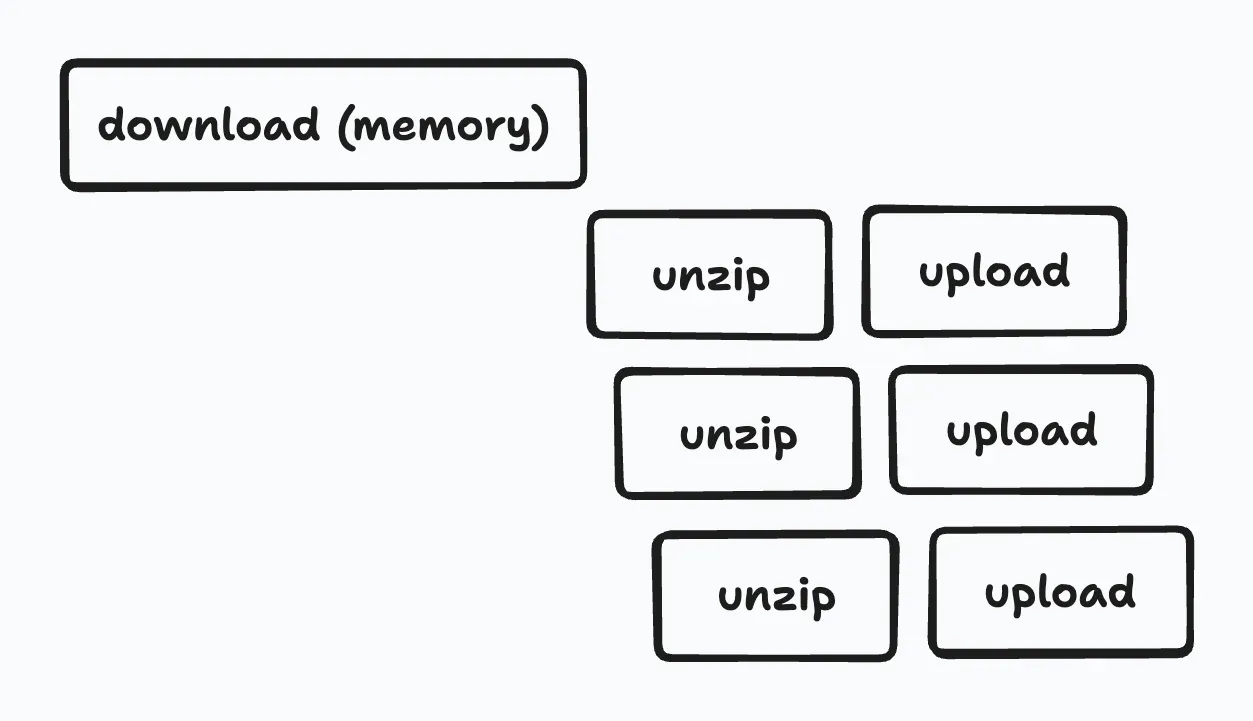
Initially, the implementation was simple: after uploading an archive file from a web browser via an API (running on Cloud Run) to GCS, a worker (also on Cloud Run) would extract the archive file entirely into memory and upload the extracted files to GCS in parallel.
This setup had the following issues, failing to meet the requirements:
- The zip file was too large, causing timeouts during the upload to the Cloud Run API server.
- The zip file was too large, leading to insufficient memory in the worker (Go requires loading the entire zip file into memory as
io.ReaderAtfor extraction). - The zip file was too large, resulting in very long processing times and subsequent timeouts (sometimes taking tens of hours).
Initial Architecture Limitations:
- Could only handle zip files up to 4GB
Improvement Goal:
- We set "being able to extract 10GB zip files" as our first milestone for system enhancement.
Direct Upload from Web Browser to GCS
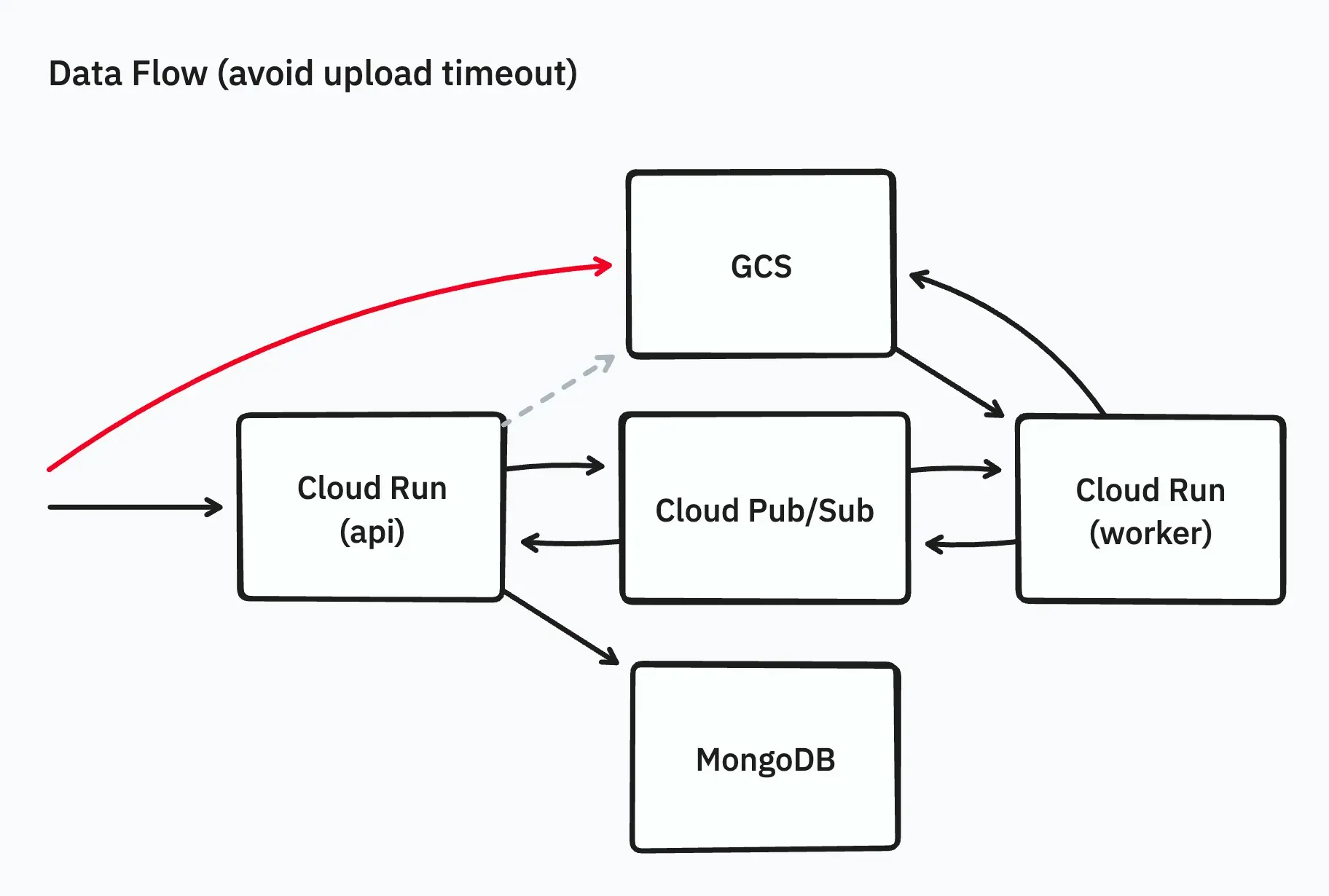
The first step was to change the system so that the frontend would no longer upload archive files directly to the API server but instead use signed URLs issued by GCS, allowing direct upload from the web browser to GCS.
This change avoided Cloud Run timeouts and reduced unnecessary data transfers, enabling the upload of large archive files to GCS. However, the following issues remained:
- Large memory requirements for the worker.
- Long processing times for the worker.
Making the Extraction Process Resumable
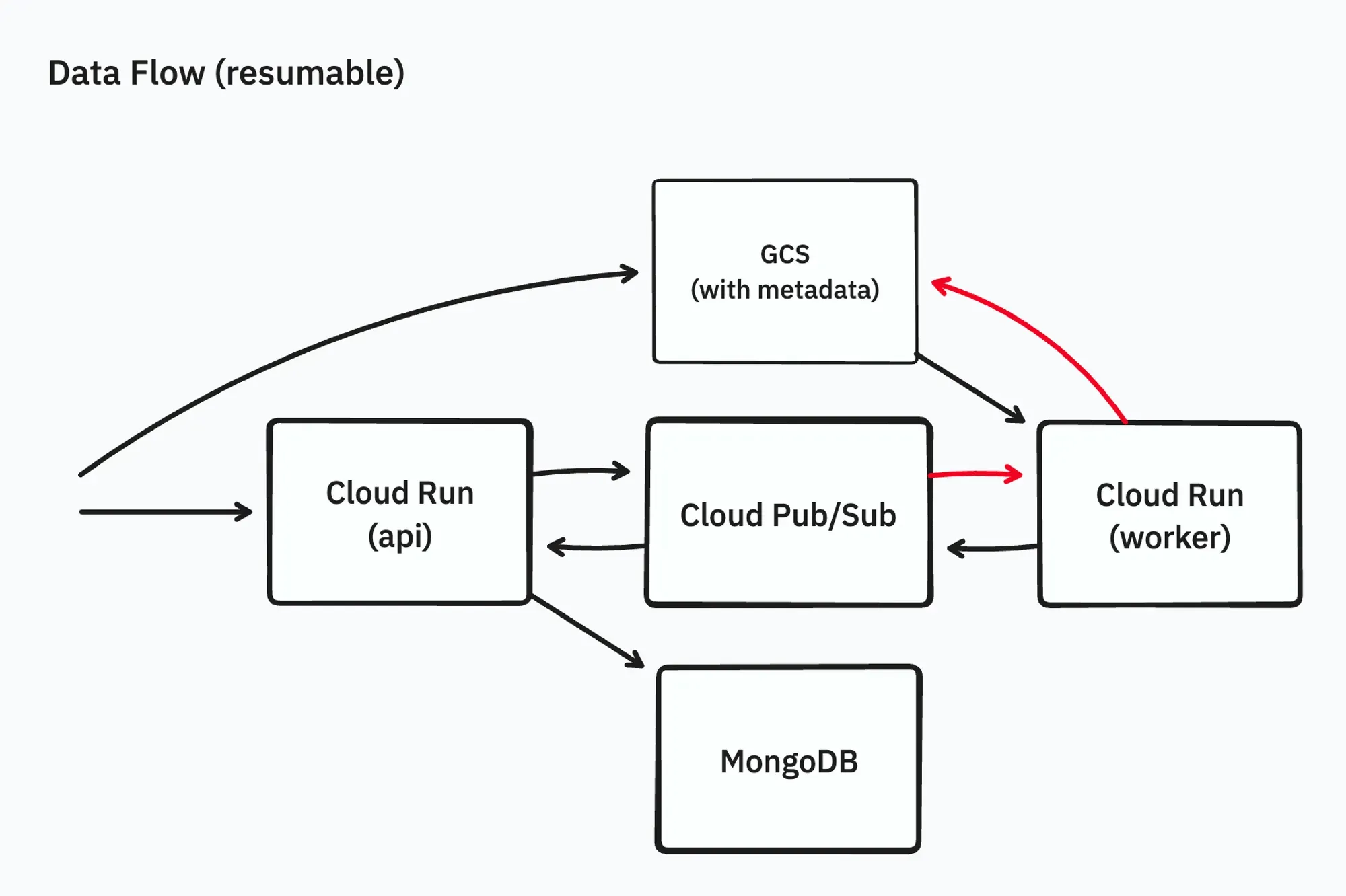
Next, to avoid timeouts during extraction, we made the process resumable even if interrupted. By writing metadata on GCS indicating the progress, the extraction process can be resumed. To simplify the information on progress, we serialized the extraction process.
We relied on Cloud Pub/Sub retry capabilities to handle the resumable process, allowing us to extract 10GB zip files. However, this approach had the following issues:
- Even when resuming, certain compression formats required full decompression, causing time-consuming seek operations.
- Unpredictable behavior when running workers in parallel.
Additionally, when a large number of files were involved, saving the extraction results or file lists to the database caused issues, with API servers failing to function correctly.
Improving Internal Representation of File Lists
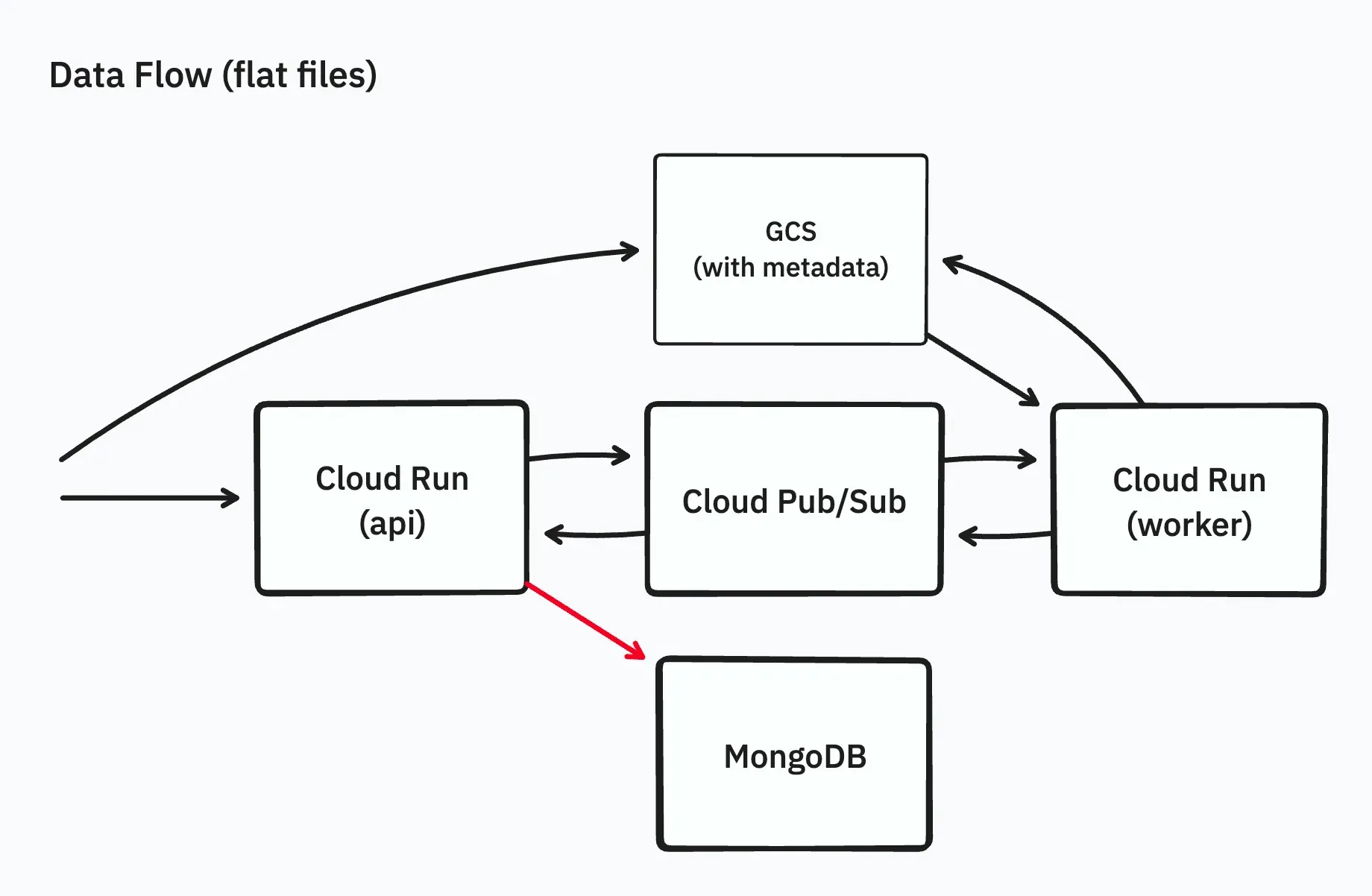
The issue with saving the file list from archive files stemmed from the fact that each document in MongoDB was stored as a tree structure, and cases with over 200,000 files hit the 16MB document limit of MongoDB.
To resolve this, we grouped 1,000 files per document and saved them as a flat array instead of a tree. The response to the frontend converted the flat list back into a tree format. We also optimized the algorithm for converting the flat list to a tree, addressing performance issues.
With these changes, we achieved the milestone of "extracting 10GB zip files."
However, with this architecture, where the entire archive file's contents are loaded into memory, the 32GB memory limit of Cloud Run made it impossible to achieve the goal of "extracting 100GB zip files."
Using Cloud Build for Extraction
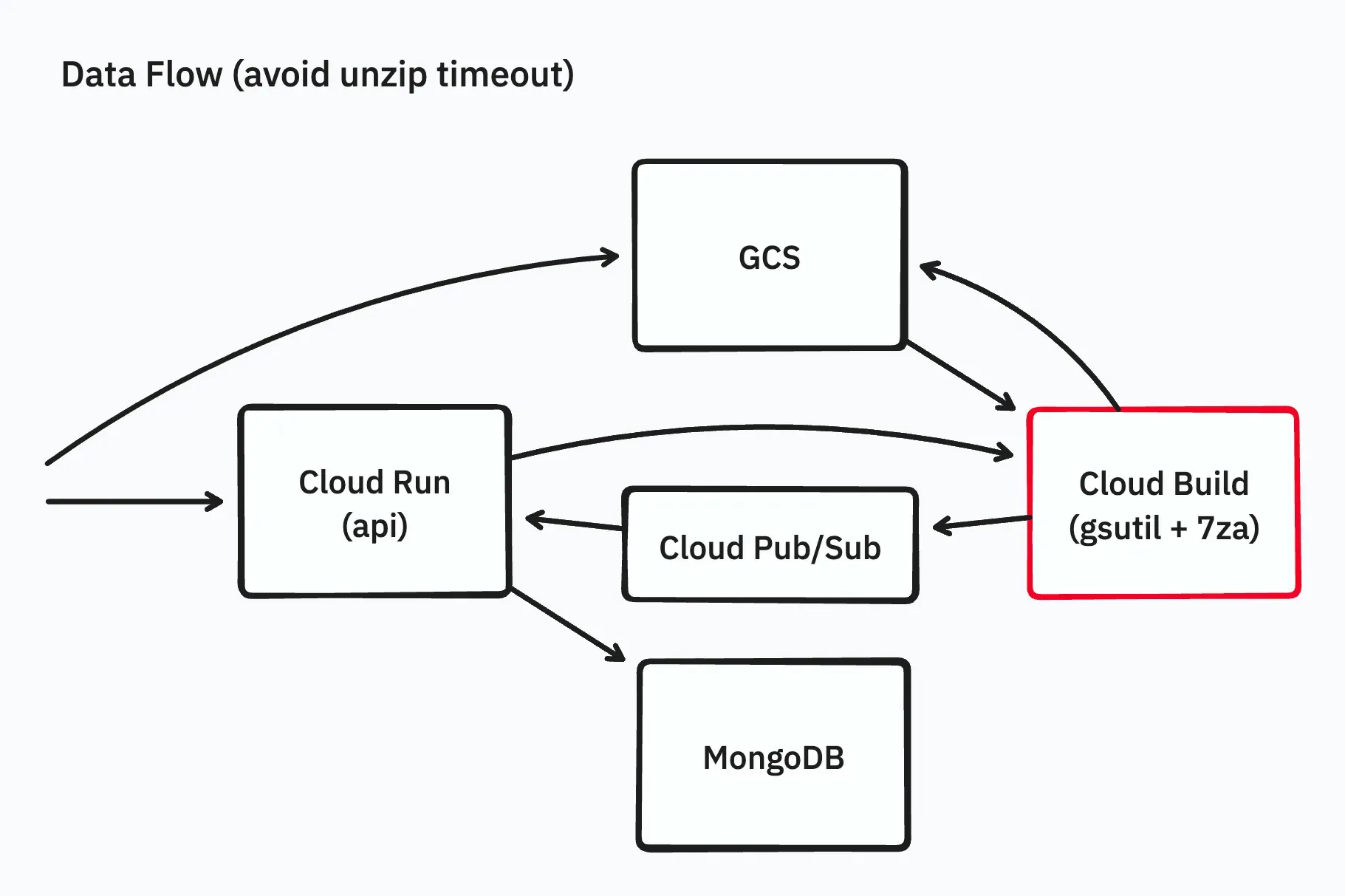
To quickly resolve issues, we decided to use Cloud Build as the execution platform for workers instead of Cloud Run. Cloud Build offers longer timeout settings (up to 24 hours) and can run arbitrary Docker images for processing.
Additionally, we changed the process to use a combination of gsutil for downloading/uploading and 7za for extraction.
This change allowed us to avoid timeout issues, and the process completed successfully. However, using the parallelization option of gsutil (and gcloud storage command), the processing time was longer than expected.
To address this, we hypothesized the following potential causes for the delay and decided to investigate:
- gsutil's parallelization not functioning correctly.
- Delays due to uneven prefixes in upload order.
Parallelizing Uploads
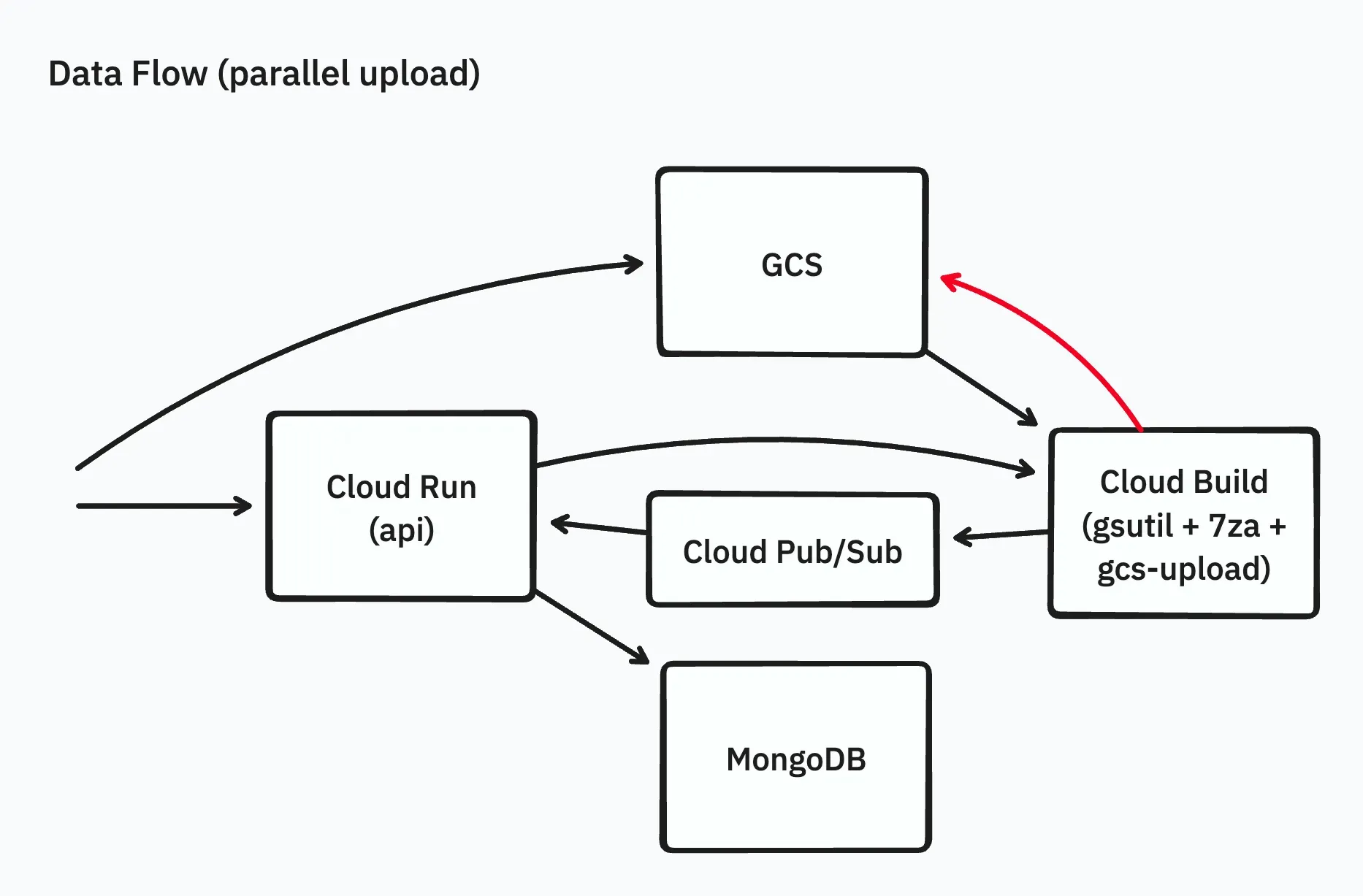
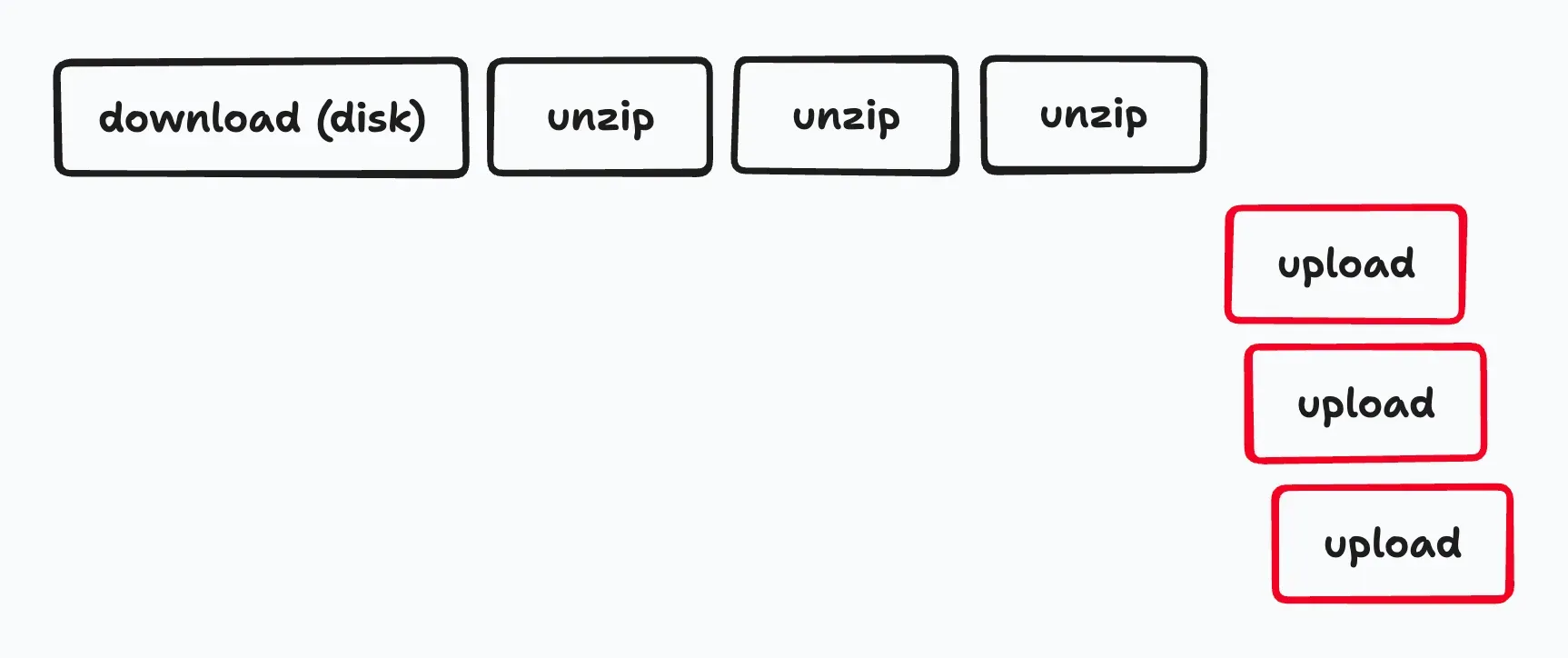
To parallelize the upload process in gsutil, we implemented a tool in Go called gcs-upload and experimented with it. Below is an excerpt from the source code of gcs-upload:
ctx := context.Background()
gcs, err := storage.NewClient(ctx)
if err != nil {
return fmt.Errorf("storage client: %w", err)
}
bucket := gcs.Bucket(dest.Hostname())
uploadBufPool := sync.Pool{
New: func() any {
return make([]byte, *bufSize)
},
}
var count atomic.Int64
uploadsStart := time.Now()
eg, ctx := errgroup.WithContext(ctx)
eg.SetLimit(*n)
listFileScanner := bufio.NewScanner(listFile)
for listFileScanner.Scan() {
f := listFileScanner.Text()
eg.Go(func() error {
select {
case <-ctx.Done():
return nil
default:
}
r, err := os.Open(filepath.Join(*dir, f))
if err != nil {
return fmt.Errorf("open upload file: %w", err)
}
defer r.Close()
name := path.Join(dest.Path[1:], filepath.ToSlash(f))
o := bucket.Object(name).Retryer(storage.WithPolicy(storage.RetryAlways))
w := o.NewWriter(ctx)
w.ChunkSize = int(*chunkSize)
defer w.Close()
buf := uploadBufPool.Get().([]byte)
defer uploadBufPool.Put(buf)
var start time.Time
if *verbose {
start = time.Now()
}
if _, err := io.CopyBuffer(w, r, buf); err != nil {
return fmt.Errorf("upload: %w", err)
}
if err := w.Close(); err != nil {
return fmt.Errorf("close writer: %w", err)
}
c := count.Add(1)
if *gcInterval > 0 && int(c)%*gcInterval == 0 {
runtime.GC()
}
if *verbose {
log.Printf("%7d: -> %s: %s", c, "gs://"+path.Join(o.BucketName(), o.ObjectName()), time.Now().Sub(start))
}
return nil
})
}
if err := eg.Wait(); err != nil {
return fmt.Errorf("uploads: %w", err)
}
We implemented gcs-upload for parallel uploads, which proved to be significantly faster than gsutil. In our tests, uploading 270,000 files with 48 parallel processes took 976 minutes using gsutil, but only 9 minutes with gcs-upload - a 100-fold speed improvement.
For those using gsutil for GCS uploads, implementing a similar parallel upload process could substantially accelerate operations. When parallelizing GCS uploads with Go, we found that the cloud.google.com/go/storage Writer already includes an internal buffer, eliminating the need for a custom buffer. However, be aware that the default buffer size is 16MB, which may lead to OOM issues if uploading with 1,000 parallel processes.
We initially hypothesized that upload order might cause hotspots, but this was disproved when implementing a random shuffle function showed no effect on performance.
Through this validation, we concluded that a custom parallel upload implementation could indeed significantly improve speed. However, our actual use cases revealed a new challenge: some archive files were so large that their extracted contents exceeded 1TB, necessitating an architectural change.
Concurrent Extraction and Upload
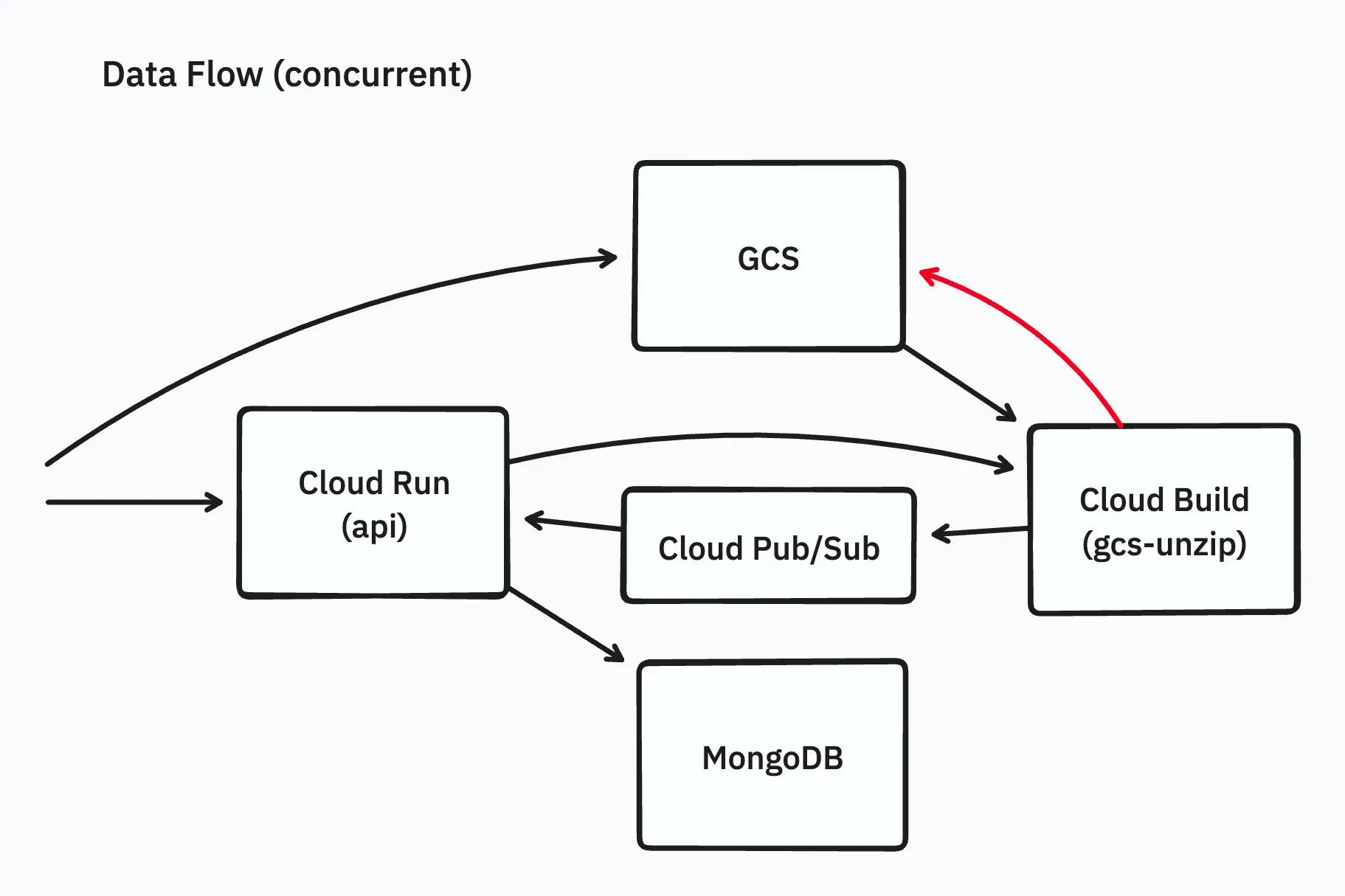
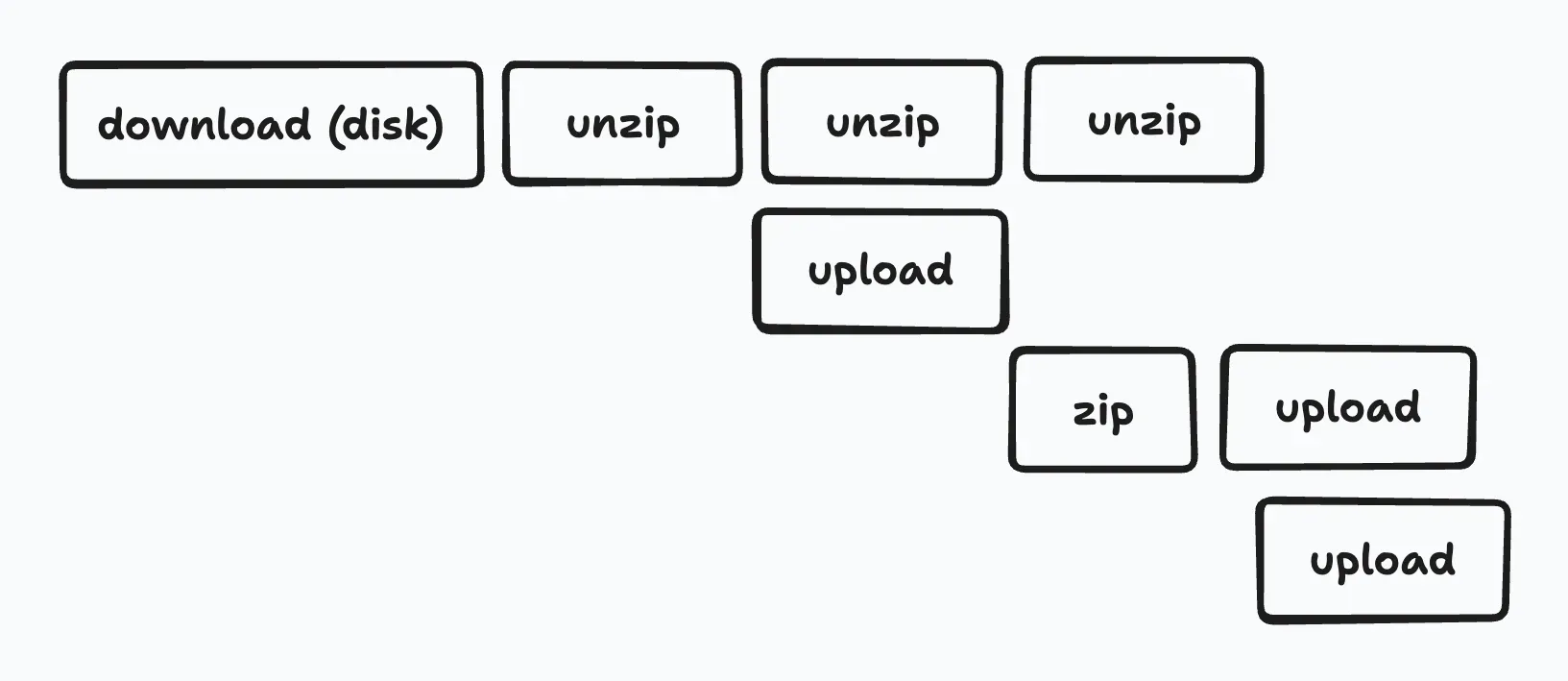
To minimize disk space usage during extraction, we implemented a tool (gcs-unzip) that handles extraction and upload concurrently.
By uploading each extracted file immediately and deleting it once the upload is complete, we avoided disk space issues.
While implementing this naively could lead to excessive disk usage during parallel uploads, using semaphores helped limit disk space usage with minimal implementation.
During large file uploads to GCS, storage costs need consideration.
In our use case, the archive files contained many XML files that compress well. To save on storage costs, we implemented functionality to upload files that met certain conditions in a gzip-compressed state.
GCS allows for uploading gzip-compressed files, reducing storage costs while maintaining the same download fees, making this a beneficial approach for use cases like ours.
https://cloud.google.com/storage/docs/transcoding?hl=en
We also worked on optimizing the internal sevenzip and xz libraries, submitting pull requests that, while not yet merged, achieved a 20% speed improvement in the xz library.
https://github.com/ulikunitz/xz/pull/55
With these efforts, we were able to extract and handle zip files significantly larger than 100GB, successfully extracting up to 500GB zip files.
Lessons Learned
- Importance of re-implementation and validation: Even when using existing tools, it's crucial to re-implement and validate speed optimizations. This process can reveal unexpected performance gains and ensure the solution is tailored to specific use cases.
- Go-specific considerations for GCS uploads: When parallelizing GCS uploads in Go, pay attention to the Writer's chunk size. This parameter can significantly impact performance and memory usage, especially in high-concurrency scenarios.
- GCS gzip Transcoding for specific use cases: In situations with high compression rates and fewer downloads, consider utilizing GCS gzip Transcoding. This feature can offer benefits in terms of storage efficiency and transfer speeds.
- Continuous improvement of tools and libraries: There is always potential for optimization in commonly used tools and libraries. Regular review and benchmarking of these components can lead to substantial performance improvements in your overall system.
Future Outlook
While Cloud Build offers advantages like ease of use, it's primarily designed for CI/CD purposes. For our specific use case of extracting zip/7z files, we're planning to migrate to either Cloud Run Jobs or Cloud Batch in the future.
We've identified two key areas for process improvement:
- Eliminating the need to download entire archive files to disk:
- Goal: Read and stream file contents directly
- Enhancing parallel upload efficiency:
- Implement gzip compression for files awaiting upload
These changes aim to optimize our file extraction and upload processes, moving beyond the limitations of our current Cloud Build setup.
Eukaryaでは様々な職種で採用を行っています!OSSにコントリビュートしていただける皆様からの応募をお待ちしております!
Eukarya is hiring for various positions! We are looking forward to your application from everyone who can contribute to OSS!
Eukaryaは、Re:Earthと呼ばれるWebGISのSaaSの開発運営・研究開発を行っています。Web上で3Dを含むGIS(地図アプリの公開、データ管理、データ変換等)に関するあらゆる業務を完結できることを目指しています。ソースコードはほとんどOSSとしてGitHubで公開されています。
➔ Re:Earth / ➔ Eukarya / ➔ note / ➔ GitHub
Eukarya is developing and operating a WebGIS SaaS called Re:Earth. We aim to complete all GIS-related tasks including 3D (such as publishing map applications, data management, and data conversion) on the web. Most of the source code is published on GitHub as OSS.